
Rough evolving notes to explore my research interests in ML and other fields.
This post is an evolving personal note. I've written it carefully to organize and account for my tastes in research. I've listed several papers that I frequently revisit for guidance. The post is an expression of my faith in these papers; it is not a research proposal or a document to present new challenges. My opinions are not intended to have a broad appeal. In fact, I may not stand by some of this content in the future! Still, it may be of interest to early-career researchers, or people trying to figure out what directions to pursue in ML research.
I've been experimenting with Machine Learning for quite some time. It started as a passing interest in early 2017 when I participated in a hackathon at Microsoft. The possibilities and affordances of ML enthralled me. Since then, I've engaged with several ML projects, undertaken serious coursework, and worked as an intern and later as an employee in ML research. Over the years, I've developed a taste for specific directions and watched my interest wane in others. In this post, I've exhaustively listed directions that continue to thrill me.
To do so, I've chosen papers across subfields I've read multiple times.
These papers, which I'll call exemplars for the sake of this post, have
stood the test-of-time (for me) and shaped the way I perceive research.
Test-of-time is perhaps an overreach – I've hardly read papers from a
decade ago! But it's a useful metaphor and also serves to reflect how
quickly the field has evolved in the past decade. Importantly, when I
speak of exemplars, I don't want to strip them of the human agency that
brought them to life. Each of these works is driven by researchers whose
choices, care, and creativity inspire me, and I'll try to acknowledge
them wherever possible.
Another useful metaphor if you have a technical bent: think of this post as a Python library. Let's say I want to draft a "Related Work" section. I'd import exemplars with a fantastic description of previous work and repurpose the style or structure in my writeup. The same goes for experiments, figures, tables, graphs, or even the author contributions section. These exemplars serve as vital checkpoints in my memory for each subfield, helping me calibrate my responses to new research. This is quite enabling as a filter, especially now that ML is seeing an incredible surge of papers. I rarely read the latest papers unless they strongly compel me. This compulsion is a function of the obsessive preferences I've cultivated through exemplars.
To be clear, not all exemplars come from ML. Over the years, I've also
grown interested in
sociology, history, and
development studies. Also, not all exemplars serve a strong technical
purpose. Some appear simply for their bold perspectives, graceful prose or
because they remind me of a time when I could read leisurely without
purpose. I haven't tracked the counts, but most exemplars are celebrated
and well-cited by the community. The bib file is available
here.
Of course, citation count doesn't alone indicate exemplary work. Pedagogical clarity and aesthetic value are just as crucial. Every good paper is a box of surprises. It should shock us that the proposed methodology even works. All odds are stacked against it. So, what's the sorcery underneath? The sorcery lies in its brave assumptions. I don't know how to quantify any of this, but all exemplars have a sense of wonder that makes them memorable. They hold epistemic weight in that they tend to determine the culture, aesthetics, and trajectory of entire subfields.
Obsessive inclinations in problem space are generally discouraged. We're often nudged to reach an unexciting compromise, to find a balance between what we're passionate about and what's practical. Corporations naturally lean toward consumer-friendly problems that yield profits quickly, efficiently, and predictably. Academia pulls us toward what's trending and what will land in a top conference. Non-profits, too, care deeply about their users and impact, and that doesn't leave much room for pursuing an obscure problem simply because it's beautiful or because we find it endlessly surprising. It feels almost out of place to say, "I'm working on this because I love it," without any attachment to user impact or utility. Yet, problem spaces deserve our compassion and curiosity. So, I'd like this post to be a record of my technical fascinations, unmarred by utilitarian aspects.
To fulfil my fascinations till now, I've meandered quite a bit in the problem space without steadfast commitment to any particular direction. Now, I seek paths that I can uniquely pull off, hoping to weave together threads from past inquiries. Uniqueness can sometimes lie in merging overlooked insights. This approach might seem like low-hanging fruit, but if it uncovers new perspectives, it's well worth the reach. I recall a conversation with my Time Series professor about the EM algorithm – a routine tool for us in ML, yet to him, it unveiled an array of fresh possibilities. His work in frontier research could have flourished with scalable EM algorithms, which modern toolboxes like Pyro enable today, but he hadn't heard of them! Not all experts navigate innovations outside their domain, and when we bridge these worlds, it will lead to exciting discoveries.
Having said that, I primarily want to bring forth uniqueness with an unwavering focus on the real world. I want my work to genuinely connect with communities, not as an afterthought but as a principle embedded within the modelling process itself. I'm striving for more than just checklists or rubrics; I want these values to be encoded in ways that reach beyond technical formalisms, though I can't fully articulate it yet. All of this may come across as a narcissistic exercise, and perhaps it is. But it's one that, I feel, adds dignity to our pursuit. We all deserve to take pride and purpose in our work.
Putting this post together has been rewarding on multiple levels. It helped me emotionally concretize the directions I find most promising and made me realize how much I'm drawn to purposeful modelling guided by scientific principles, experimentation, and mathematical clarity. For instance, rather than carelessly tossing in an attention layer for its interpretability (a contested claim, but that's for later), I find myself drawn to building smaller, principled models with a generative backbone. I'm excited by the less-explored directions that resonate with my local context and align with my political and moral wills. I believe the following characteristics in model design will yield formidable results in the future:
1) formulated and deployed with care for local communities,
2) built
with domain-dependent inductive biases,
3) small scale; both in
parameter count and training data size,
4) adequately specified while
graciously leaving room for critique,
5) controllable and
interpretable; likely through discrete latent variables,
6) inferred
via (semi)differentiable approximate Bayesian procedures.
Quick disclaimer: I don't think modern ML directions lack principles or
control. And what's so controllable about principled models, anyway? I'm
not coding autodiff from scratch or handcrafting optimizers with
meticulous care. I am not sweating over gradient variances for ADAM;
PyTorch handles that. Plus, principled methods aren't always practically
valuable – like BNNs, which haven't yet proven useful. Even the promised
uncertainty quantification in BNNs is a bit overrated. There is always an
approximation or trickery underneath principled methods that enable them
to function in production. So, I do recognize the fragility of my claims,
but I prefer not to dive blindly into methods without regard for
misspecification.
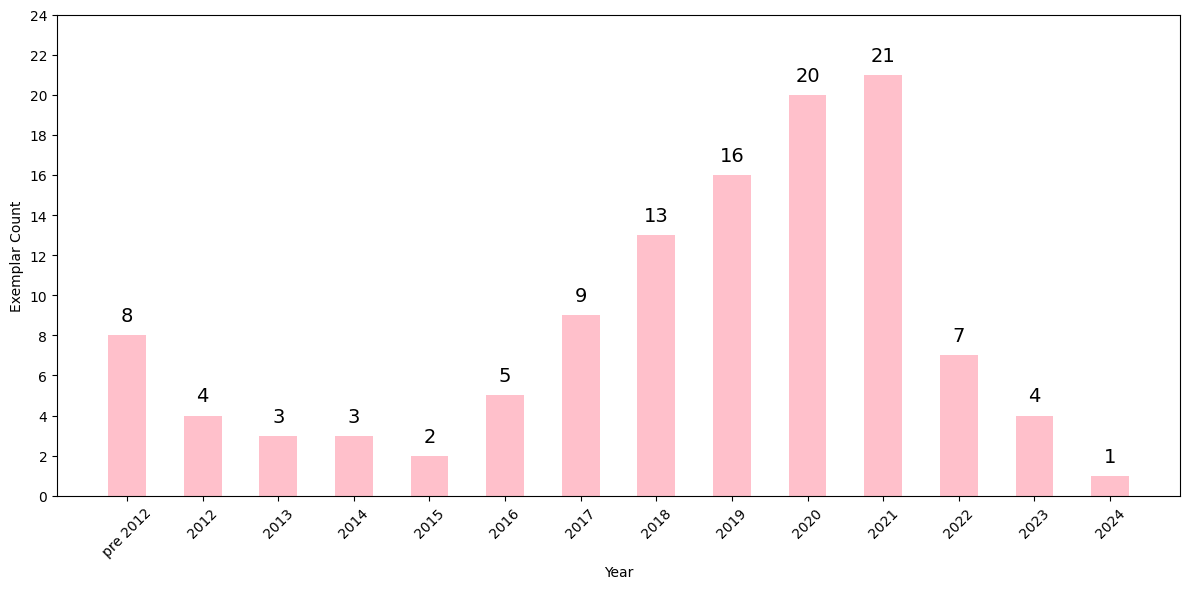
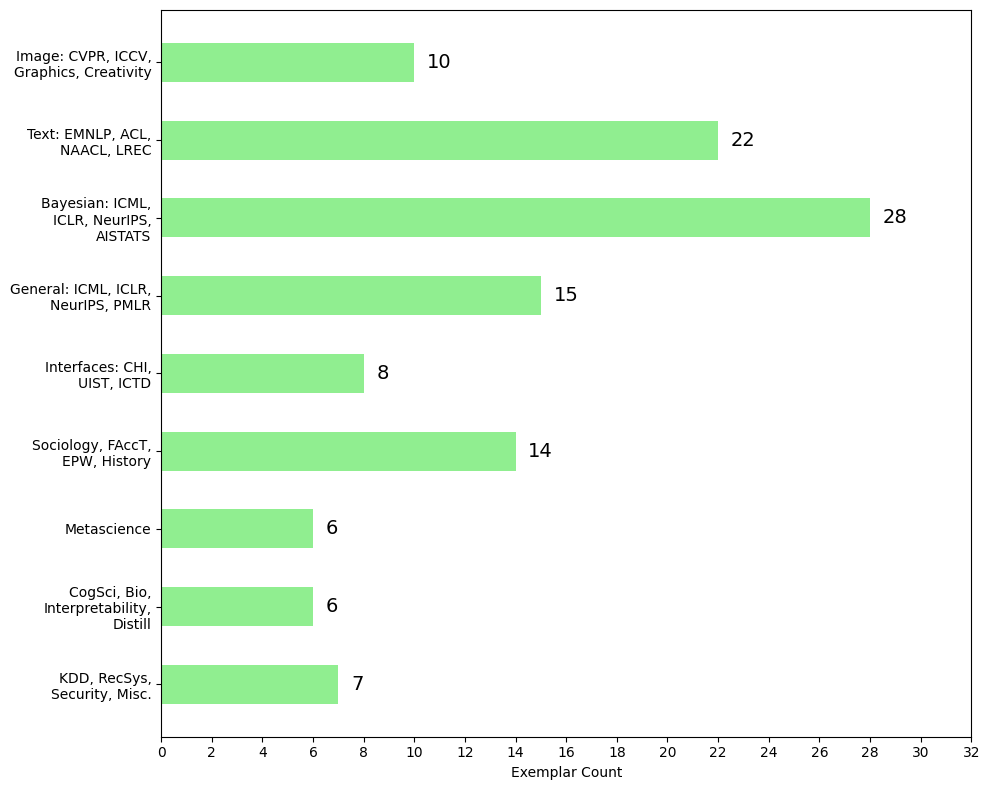
Structuring this post was quite challenging, given the variety of directions it spans. I've clustered exemplars around broad themes and arranged them to resemble a typical ML research pipeline. Admittedly, it is not perfect, but I hope you will find the arrangement useful. Each section stands independently, so you can always switch between them without worrying about the context. Alongside each paper, you'll find a brief reflection – not a summary of the work, but an expression of my fondness for it. Occasionally, you might stumble upon a few provocative rants where I describe my interactions with certain subfields.
I enjoy leisurely reading about the generation of scientific artefacts. This usually happens through biographies of scientists, like this amazing book on Von Neumann's life. Apart from being inspirational, these readings also inform me about my own position within the research landscape and help me cultivate better practices. Historical and occasionally philosophical perspectives ground me and remind me not to get swept up by passing trends.
My guiding principle is simple: I view research as an extension of my learning process. When I hit a roadblock in my learning that I can't resolve, I frantically search textbooks, papers, StackOverflow threads, or discuss with peers. If I'm still stuck, I know I've stumbled upon something worthwhile for research. The next steps follow naturally: make assumptions, design empirically quantifiable models, and measure the gains. Of course, the process isn't as clean as this sounds, but it's a helpful summary.
As a consequence of this research-as-learning approach, I find it invaluable to engage in teaching or other educational community services. Beyond keeping the gears turning, they offer a chance to review my progress. It is such a pleasure to see our ideas resonate and radiate through others.
Baldwin, Melinda. "Scientific autonomy, public accountability, and the
rise of "peer review" in the Cold War United States." Isis 109.3
(2018).
I found this text while trying to rationalise my paper rejections
as a failure of peer-review. It is a quick historical recap of how
peer-review was originally used to control public funding in science
without engaging on actual scientific merits. It tilted research to be
more utilitarian, limiting the space for unconventional ideas.
Lipton, Zachary C., and Jacob Steinhardt. "Troubling Trends in Machine
Learning Scholarship: Some ML papers suffer from flaws that could
mislead the public and stymie future research." Queue 17.1 (2019).
Examples of labs inflating their papers with unnecessary math.
Plus, falsely attributing gains to methodology when the real reason is
data mismanagement or hyperparameter choices.
Sutherland, Ivan. "Technology and courage." Perspectives 96 (1996):
1.
Research must be brave and intensely personal. Sometimes, pursuing
excellence can be boring, especially if there is no appetite for risk.
Another popular piece of advice is Richard Hamming's
You and Your Research. I find Sutherland's words more palpable and less paternalistic than
Hamming's.
Andy Matuschak. "Cultivating depth and stillness in research". (2023).
Link
Andy writes so eloquently. I make it a point to read his work
whenever it is published. This particular post deals with the emotional
aspects of doing research. Research can get quite boring after a point!
Creative bursts are rare, and there is a pervasive nothingness for long
stretches. We have to be okay with it. Keep learning along the way. Enjoy
the stillness.
Whenever I need a concise introduction to a subfield, I look for relevant tutorials and surveys. They serve not only as great starting points but also as useful checkpoints to return to whenever I feel stuck. Tutorials are an underappreciated contribution. Researchers often get recognized for organising and managing them, but the content itself doesn't receive the credit it deserves. In my view, tutorials and surveys, carefully prepared in service to the reader, should be cherished even more than traditional papers.
Kim, Yoon et al. "A Tutorial on Deep Latent Variable Models of Natural
Language." EMNLP Tutorial (2018).
I've revisited this tutorial several times. It is concise,
structured, and covers all formalities of latent variable models. Each
model is paired with a memorable example and a discussion on how to
"deepify" it. I've even adopted the exact variable notations from this
tutorial in much of my own work.
Riquelme, Carlos et al. "Deep Bayesian Bandits Showdown: An Empirical
Comparison of Bayesian Deep Networks for Thompson Sampling." ICLR
(2018).
What a joy when a survey paper comes with an accompanying
repository containing datasets and basic implementations.
Ferrari Dacrema, Maurizio, Paolo Cremonesi, and Dietmar Jannach. "Are
we really making much progress? A worrying analysis of recent neural
recommendation approaches." ResSys (2019).
Probably the earliest work that revealed to me about the
replicability crisis in deep learning. Carefully arranging clusters of
papers is very crucial in surveys. This survey is a good example of it.
Baek, Jeonghun, et al. "What is wrong with scene text recognition model
comparisons? dataset and model analysis." ICCV (2019).
Another excellent survey paper. Here, the stress is on available
datasets. Also, the clustering is with respect to scene text recognition
model pipeline rather than methodological choices.
Yonatan Belinkov, Sebastian Gehrmann, and Ellie Pavlick.
"Interpretability and Analysis in Neural NLP." ACL Tutorial (2020).
Neatly distinguishes between behavioural and structural approaches
of interpretability.
Dataset preparation is a crucial, foundational activity for the scientific community. I love seeing tasks associated with non-standard datasets. For example, digitizing old books is a great means to preserve knowledge and open up new avenues of literary research. But over the years, the field has leaned into the idea that "data is the new oil". Frankly, that phrase makes me cringe a little. Do we really need to dig up all that oil? Digitization isn't always beneficial. We should focus on collecting only what's necessary rather than engaging in this unchecked, greedy hunt for data.
Anna Rogers. "Changing the World by Changing the Data." ACL (2021).
This paper has been instrumental in shaping my thinking about the
ethics of data collection. Assuming that large models can simply figure
everything out on their own is flawed. We must, therefore, curate data
carefully with purpose.
Jin-Hwa Kim, Nikita Kitaev, Xinlei Chen, Marcus Rohrbach, Byoung-Tak
Zhang, Yuandong Tian, Dhruv Batra, and Devi Parikh. "CoDraw:
Collaborative Drawing as a Testbed for Grounded Goal-driven
Communication." ACL (2019).
I came across this paper while exploring computational creativity.
It demonstrates a testbed for collecting conversational data grounded in
clipart. Even well-known structures like cliparts can have several
deviations. The potential for diversity is immense.
Semih Yagcioglu, Aykut Erdem, Erkut Erdem, and Nazli Ikizler-Cinbis.
"RecipeQA: A Challenge Dataset for Multimodal Comprehension of Cooking
Recipes." EMNLP (2018).
I've used this dataset multiple times in my projects. I appreciate
the range of tasks it offers, particularly the temporal ones. Ingeniously
crafted.
Alexander Rush. "The Annotated Transformer." In Proceedings of Workshop
for NLP Open Source Software NLP-OSS (2018).
Link
Lovely pedagogical experiment in paper reproduction. I'm a huge
admirer of Sasha's work.
Sai Muralidhar Jayanthi, Danish Pruthi, and Graham Neubig. "NeuSpell: A
Neural Spelling Correction Toolkit." EMNLP System Demonstrations
(2020).
A neat repository offering a range of models for experimentation,
from simple non-neural approaches to more advanced ones like transformers.
I'm sure there are better tools for spell correction now, but this
repository structure has stuck with me for its versatility. More broadly,
I feel NLP repositories are among the best maintained in the ML community,
and the quality of open-source tooling has improved massively.
Blondel, Mathieu, et al. "Efficient and modular implicit
differentiation." NeurIPS (2022).
Implicit function theorem is such a powerful idea we often take for
granted. It could be applied in dataset distillation, reparameterization
trick, differentiable convex optimization layers, and many more places.
This contribution incorporates decorators in JAX for implicit autodiff.
Very effective pseudocode.
Dangel, Felix, Frederik Kunstner, and Philipp Hennig. "Backpack:
Packing more into backprop." ICLR (2020).
Pytorch or JAX take up the burden of efficient autodiff for us, but
it is a faustian pact. We lose crucial information like gradients per each
data point. We lose the ability to think creatively about new optimizers
or new paradigms of computing. Backpack is a neat decorator that brings
back some control to our hands.
PMI forms the heart of my intellectual pursuits. It's the landscape I return to whenever something feels uncertain. It is a familiar terrain of ideas and proofs where I plant my checkpoints. These checkpoints are like mental milestones; places where I pause, reflect, and recalibrate when faced with difficult problems. I map new concepts and examples back to PMI's structured framework and find solace in its coherence. This approach has been ingrained in me since my undergraduate days, thanks to formative courses and discussions with Prof. Piyush Rai, whose influence has guided much of my journey.
What captivates me about PMI is the clarity, precision, and deliberate decision-making that is embedded in its methodology. It contrasts sharply with the often expedient choices we see in ML, whether in optimizers, hyperparameters, or network structures. While some find the "ML is alchemy" argument amusing, I much prefer the control PMI offers – the ability to carefully craft inductive biases and purposeful priors. This isn't to say randomness is absent in PMI; rather, it is acknowledged and even quantified. The real charm, for me, lies in how several seemingly arbitrary ML choices can be reasoned as relaxations of PMI methods, revealing deep connections that expand our knowledge.
Today, PMI seems to have lost some of its prominence. It's often tucked away in textbooks (Murphy!) or confined to lecture notes as ML moves towards models dominated by large size and empirical success. I sometimes imagine future papers rediscovering PMI with titles like "Neural Networks are Probabilistic Models in Disguise," much like how SVMs are resurrected every now and then. But even now, celebrated models like DALL-E, which is rooted in VQVAE, owe much of their success to probabilistic thinking. This underlying structure, even when not recognized explicitly in media, continues to shape breakthroughs in ML.
To be clear, I am not dismissive of the modern advances and technical achievements in ML, and I don't see PMI and ML as competing fields. In fact, synergy between the two is always welcome! I recognize that an arguable implication of the previous paragraph is the territorial capture of ML by PMI, similar to how some statisticians argue that all of ML is merely statistics. This view can be limiting for two reasons. First, it creates an illusion that every advance in ML is simply a derivative of PMI methods, stifling critical engagement with other approaches. Second, the broad applicability of PMI, though a strength, also dilutes the field in some ways, blurring its distinctiveness. Both factors, combined with the rush towards larger models fuelled by vast data and resources, have perhaps unproductively blocked the field from following its core essence of careful, principled reasoning in small-data regimes.
For instance, there isn't much talk of missing data anymore, with a misplaced assumption of data abundance across all use-cases. Some of my favourite models, like PPCA, were designed explicitly for missing data constraints. The idea that we can learn meaningfully even with limited, incomplete data remains, for me, one of PMI's most powerful contributions. Today, practitioners reflexively ramp up data collection procedures when faced with data scarcity. Their belief lies in the ability of general-purpose transformers to extract richer and predictively stronger priors from data than what PMI-style handcrafted priors offer. Empirically, I cannot argue against transformers, and I can only feel bitter at the derision of PMI. I can, however, cautiously say that there are scenarios where dramatically increasing computation is infeasible, where data collection is morally unjustifiable. Maybe PMI could offer its powers in those cases.
Discrete latent variable models, mixture models, and techniques aimed at smaller, more nuanced data regimes feel increasingly sidelined. These are the models that explicitly address the intricacies of communities and individuals, the ones that guide us in exploratory data analyses and bridge disciplines, much like topic models once did. A hallmark of a good research idea is its ability to lend itself to pedagogy, and probabilistic models have stood the test of time in this regard. Despite the waning popularity, mixture models, topic models, and PPCA continue to be foundational in advanced ML courses. With a renewed emphasis on the elegance and accessibility of these methods, we could strategically attract a broader audience to PMI's strengths.
Once again, I want to emphasize that I'm thrilled by the progress and paradigm in ML. I certainly wouldn't go back to modelling words as one-hot vectors the size of the vocabulary. Give me dense GloVe vectors any day! In fact, "deepified" probabilistic models can be crafted to be more efficient, both in size and computational effort, than traditional models. This synergistic energy should be embraced rather than digging our toes while also keeping sight of the core principles that define PMI.
Perhaps I'm not reading widely enough, or maybe there are probabilistic models out there quietly making strides without much fanfare. It's possible I'm being too hesitant to embrace the "bitter lessons" so widely accepted today. But I hold firm to the belief that my taste in research means standing by simple, principled ideas, trusting in them bravely, and cherishing their triumphs.
Blei, David & Ng, Andrew & Jordan, Michael. "Latent Dirichlet
Allocation." JMLR (2001).
Universally celebrated model, inspiring research for more than two
decades. Compact generative story, discussion on exchangeability, and
Figure 4 Simplex have strong pedagogical appeal.
Zhou, Mingyuan, et al. "Beta-negative binomial process and Poisson
factor analysis." AISTATS (2012).
LDA can be viewed as matrix factorization by collapsing latent
variables. How cool! This opens the door to applying advances in
recommender systems to document count matrices.
Liang, Dawen, et al. "Modeling User Exposure in Recommendation." WWW
(2016).
An elegant latent variable model for matrix factorization. So
simple and comforting retrospectively.
Van Den Oord, Aaron, and Oriol Vinyals. "Neural Discrete Representation
Learning." NeurIPS (2017).
What if the document vectors in LDA are discrete and topic vectors
form a codebook? I don't know if this is a popular view, and my
interpretation by connecting to LDA is likely wrong. But I enjoy thinking
along these lines before hunting for dissimilarities.
Brian Kulis and Michael I. Jordan. "Revisiting k-means: New Algorithms
via Bayesian Nonparametrics." ICML (2012).
Design a generative story with Dirichlet Process prior and infer
from it. A happy byproduct is an improved k-means algorithm wherein we
need not explicitly set hyperparameter k! To me, this paper is strong
evidence for taking the Bayesian route, and then making a few assumptions
(like small variance) to arrive at faster, scalable algorithms.
I try to keep track of inference techniques from first principles. Ascending along the gradients of log marginal likelihood is the classical workhorse of probabilistic inference. It can also be seen as a minimization of KL divergence with true distribution. Computation of these gradients invariably involves approximating the posterior probabilities of parameters. What ensues is a series of progressive slicing and dicing of these principles.
Adnan Darwiche. "A differential approach to inference in Bayesian
networks." J. ACM 50, 3 (May 2003), 280–305.
https://doi.org/10.1145/765568.765570.
We can make several interesting queries by promptly backpropagating
through log marginal likelihood with some luck. I was introduced to this
work through Sasha Rush's
post.
Sam Wiseman, Stuart Shieber, and Alexander Rush. "Learning Neural
Templates for Text Generation." EMNLP (2018).
Case in point: Hidden Semi Markov Models with discrete latent
variables. The gradients implicitly compute posteriors.
Tipping, Michael E., and Christopher M. Bishop. "Mixtures of
Probabilistic Principal Component Analyzers." Neural computation 11.2
(1999): 443-482.
Of course, we aren't always lucky. We may desire exact posteriors
of latent variables. As long as they are tractable, we may pursue them
with EM.
Hoffman, Matthew D., et al. "Stochastic Variational Inference." JMLR
(2013).
Full posterior's tractability is hardly possible for most models.
What if the conditional posteriors are tractable? We could make the
mean-field assumption, design a variational posterior family, and compute
iterative closed-form updates for expfam models. Process batch-wise for
speedy exploration. This paper is an excellent summary. Though I have an
eerie distaste for generalized expfam models (too mathy!), I'm a huge fan
of the author.
Ranganath, Rajesh, Sean Gerrish, and David Blei. "Black box variational
inference." AISTATS (2014).
As we expand to more models, closed-form updates are not possible.
We resort to simple BBVI gradients, with some well-meaning efforts to
reduce noise. One advantage: no more iterative parameter updates; we can
parallelize!
Kingma, D. P. & Welling, M. "Auto-Encoding Variational Bayes." ICLR
(2014).
But the convergence of noisy BBVI is too slow!. What if we can be
more direct in our ascent? This paper provides a scalable way to execute
the Gaussian reparameterization trick in the context of VAEs, which are my
most favorite class of models in the entirety of ML.
Kucukelbir, Alp et al. "Automatic Differentiation Variational
Inference." JMLR (2016).
Assuming the variational family is Gaussian, can we simplify VI for
a lay practitioner? Yes! This lovely summary is replete with heartwarming
examples. I'm especially fond of the one illustrating taxi trajectories. I
haven't fully grasped the magic of autodiff yet, but I recommend this
intro.
Figurnov, Mikhail, Shakir Mohamed, and Andriy Mnih. "Implicit
reparameterization gradients." NeurIPS (2018).
Tired of the Gaussian variational family? Here, the reparam trick
works for transformations that have tractable inverse CDFs.
Chris J. Maddison, Andriy Mnih, Yee Whye Teh. "The Concrete
Distribution: A Continuous Relaxation of Discrete Random Variables."
ICLR Poster (2017).
All VI tricks we've seen so far work for continuous variables, but
what about the discrete ones? I'm endlessly curious about passing
gradients through discrete variables.
Eric Jang, Shixiang Gu, Ben Poole. "Categorical Reparameterization with
Gumbel-Softmax." ICLR Poster (2017).
How incredible that two separate teams arrived at the same idea
around the same time! This approach is less rigorous but more applicable
with the straight-through estimator. SSL-VAE example in this paper is my
go-to reference to refresh these ideas.
Akash Srivastava, Charles Sutton. "Autoencoding Variational Inference
For Topic Models." ICLR Poster (2017).
Gumbel Softmax relaxation works for the multinomial case but falls
short for Dirichlet variables. What I find particularly appealing about
this paper, beyond the relaxations it introduces, is the boldness,
authority, and directness in its language.
Rainforth, Tom, et al. "Tighter variational bounds are not necessarily
better." ICML (2018).
I'm not terribly inclined to theoretical exercises, but this one
stuck with me. Perhaps because it is interactive and not merely an
inactionable subtlety. A whole section is dedicated to practical
derivations of estimators from their theory.
Ruiz, Francisco, and Michalis Titsias. "A contrastive divergence for
combining variational inference and mcmc." ICML (2019).
Before we proceed to sampling, I have to highlight this delightful
paper. It's not popular, but it is pedagogically significant to me. It
brings forth an interplay of many concepts we've seen: BBVI, reparam
trick, penalizing tight ELBOs, and a healthy dose of sampling. Some might
scorn the merging of ideas as low-hanging fruit, but I disagree. When done
thoughtfully, it can be a worthwhile exercise revealing valuable insights.
None of the VI methods I described above are free of sampling. They involve Monte Carlo estimation in some form, which demands efficient sampling from variational posteriors. Before I list my favourite papers on sampling, I want to stress an important chain of connections. We know that sampling (pSGLD in particular) is an exploration of the posterior distribution. It turns out that the final form of the Markov chain expression strikingly resembles another famous expression - the stochastic gradient descent! Backpropagation and SGD are the workhorses of ML. Effectively, we can intuit that descending along the weight gradients in a neural network mirrors the exploration of the posterior distribution of those weights. So, SGD can indeed be viewed as an approximate form of probabilistic inference.
Betancourt, Michael. "A Conceptual Introduction to Hamiltonian Monte
Carlo." 10.48550/arXiv.1701.02434. (2017).
The visual metaphors of high-dimensional sampling and typical sets
in this writeup are incredibly insightful. I cannot overstate how helpful
they've been for my understanding.
Dougal Maclaurin and Ryan P. Adams. "Firefly Monte Carlo: exact MCMC
with subsets of data." IJCAI, (2015).
Not super famous, but another paper I admire for its distinctive
Firefly metaphor and smart use of auxiliary latent variables. It's the
kind of work I wish I had done. How pleasurable it must have been to craft
it!
Grathwohl, Will, et al. "Oops i took a gradient: Scalable sampling for
discrete distributions." ICML (2021).
Sampling for high-dimensional discrete parameters is tough: poor
mixing, errors due to continuous relaxations. Can we use the gradient
information in discrete space itself?
Lucas Theis, Aäron van den Oord, Matthias Bethge: "A note on the
evaluation of generative models." ICLR (2016).
I've often struggled with evaluating generative models at test
time. It is unclear if one has to derive a new posterior approximation
with new data, or resort to already existing posterior means. Along
similar lines, this paper asks a more fundamental question: how are we
designing continuous models for discrete images and getting away with it?!
Izmailov, Pavel, et al. "What are Bayesian neural network posteriors
really like?" ICML (2021).
Great survey. This is the kind of heavy computation work I hope
industrial labs take up more often. "HMC on a 512-TPU cluster!" Uff.
D'Amour, Alexander, et al. "Underspecification presents challenges for
credibility in modern machine learning." JMLR (2022).
Modern ML is brittle, resulting in many failures when deployed in
production. Why aren't these failures caught beforehand with validation or
test sets? The reason is that the models are grossly underspecified. This
leads to a number of models with the same structure working superbly on
test sets, offering us no way to pick a specific one. Irrelevant factors,
such as random seeds, end up influencing predictive power because we
haven't provided enough levers in our models. Perhaps we should specify
our models with stronger inductive biases – this will constrain the
plausible solution space and can lead to better feedback at test time.
These ideas resonated with me. I hope to read all the examples in this
paper someday.
Rajeswaran, Aravind, et al. "Meta-learning with implicit gradients."
NeurIPS (2019).
I read this paper because the name "iMAML" was quite catchy. The
paper was an excellent invitation to meta learning – the introduction
section was thorough and the core bilevel optimization objective was aptly
motivated. And then chain rule takes care of the rest. It's surprising to
me how adding a regularization term can bring such outsized benefits.
Wortsman, Mitchell, et al. "Learning neural network subspaces." ICML
(2021).
Can we think of a linear connector between two parameterizations of
a neural network? Is the space meaningful? If yes, can the subspace have a
solution that is better than mere ensembling? The loss objective
formulation is so harmonious and pleasant to read.
Tancik, Matthew, et al. "Fourier features let networks learn high
frequency functions in low dimensional domains." NeurIPS (2020).
This paper provided a brief overview of NTKs. I don't understand
them well, but an intuition sparked in me reading this work. Sinusoidal
encodings help in overfitting and pushing the loss as close to zero as
possible. Effectively, they can aid in image compression.
Mordvintsev, Alexander, et al. "Growing neural cellular automata."
Distill (2020).
An exciting differentiable self-organizing system. For me this is a
significant demonstration of applying backprop to rule-based disciplines
like cellular biology.
Huang, W.R., Emam, Z.A., Goldblum, M., Fowl, L.H., Terry, J.K., Huang,
F., & Goldstein, T. "Understanding Generalization through
Visualizations." ArXiv, abs/1906.03291. (2019).
I was introduced to the phrase "blessings of dimensionality" in
this paper. A visualization of the loss landscape shows large valleys: we
find ourselves inundated with local minima! Not all minima are good,
though. We could train our model to reach a bad minima that performs
amazingly well on training and validation data but poorly on "poison" test
data.
Radford, Alec, Rafal Jozefowicz, and Ilya Sutskever. "Learning to
generate reviews and discovering sentiment." arXiv preprint
arXiv:1704.01444 (2017).
A rejected ICLR submission that, in many ways, feels like the true
precursor to today's LLM advancements. OpenAI's team demonstrated how a
low-level objective of predicting the next character could still yield
high-level features, such as sentiment. Learned representations could also
classify reviews with minimal finetuning. In fact, the authors locate a
sentiment activation scalar in the hidden layer, manipulate it, and
control the generated text. This was a remarkable result with powerful
implications back then. Karpathy's
CharRNN
and similar works did vaguely locate meaningful scalars (like comma
detectors), but they weren't as strong and reliable as this paper's
sentiment unit. With this, OpenAI had all the evidence needed to simply
scale up data and model size, confident in learning rich features that can
transfer to any other task without supervision.
Miyato, Takeru, et al. "Virtual adversarial training: a regularization
method for supervised and semi-supervised learning." IEEE Transactions
on Pattern Analysis and Machine Intelligence (2018).
This paper reframes regularization by introducing KL divergence
between output distributions of unlabelled data, contrasting perturbed
with non-perturbed weights. Then comes a clever Taylor series
approximation to produce a memorable formulation. For me, this work was
the most evocative out of a flurry of works on SSL (mean teacher, mean
student, Mixmatch) in the 2016 - 2019 period.
Chen, Ting, et al. "A simple framework for contrastive learning of
visual representations." International conference on machine learning.
PMLR (2020).
A fantastic comparative study on image representation learning
methods. The tables are particularly revealing, covering self-supervision
with linear probes, semi-supervision, full supervision, dataset
variations, size adjustments, and negative sampling choices. The method
itself is terribly minimalistic; really just one twist with
stop-gradients. This paper truly shifted my perspective on the sheer power
of simple, large-scale models to dominate. It was a humbling experience,
really. And eventually made me lose some interest in this direction.
Radford, Alec, et al. "Learning transferable visual models from natural
language supervision.". PMLR (2021).
The graphs and tables in this paper are superbly illustrative. One
standout: the result showing zero-shot CLIP embeddings outperforming fully
supervised ImageNet on domain-shifted data. It left a strong impression on
me. I only wish OpenAI continued releasing more papers with this level of
detail and creativity. They have some of the most inventive minds in the
field.
Adar, Eytan, Mira Dontcheva, and Gierad Laput. "CommandSpace: Modeling
the relationships between tasks, descriptions and features." UIST
(2014).
This paper offered valuable insights while I was examining
Photoshop user logs for a project at Adobe. It spoke to the flexibility of
tokenization; how we can go beyond words and tokenize almost anything.
Here, words are tokenized along with commands (*erase*), tools (*Blur
tool*), and menus (*Layer > New Layer > Empty*). Today's
general-purpose transformers process various types of tokens: amino acids
in protein-folding research, actions and states in RL, etc.
Elizabeth Salesky, David Etter, and Matt Post. "Robust Open-Vocabulary
Translation from Visual Text Representations." EMNLP (2021).
We read words visually, so why not let our embeddings capture that,
too? The paper challenges the conventional idea that tokens should be
purely linguistic. More importantly, vistext embeddings are tolerant to
misspellings akin to humans. Words like "langauge" aren't broken into
meaningless subword tokens, and instead have an embedding that is quite
close to the correct spelling.
Erik Jones, Robin Jia, Aditi Raghunathan, and Percy Liang. "Robust
Encodings: A Framework for Combating Adversarial Typos." ACL (2020).
Attack surface and robust accuracy are clearly articulated here. We
could defend against perturbations using special encodings, but we'd lose
out on expressivity along the way. This is the tension: increasing robust
accuracy hurts standard accuracy.
Kumar, Srijan, Xikun Zhang, and Jure Leskovec. "Predicting dynamic
embedding trajectory in temporal interaction networks." KDD (2019).
User and item embeddings in a recommender system setting need not
be entirely static. They can have dynamic parts that evolve with time.
Generating media purely for the sake of it has always felt dull to me. Undoubtedly, image or text generation tasks have immense pedagogical appeal and demand unique technical skills. I can't imagine a course on VAEs without a task to generate binarized MNIST images. Several interesting NLP subtasks like translation, named entity recognition, and others can be partially solved with text generation as the overarching goal. Video generation, in particular, is an extremely challenging and worthwhile task because it requires models to implicitly internalize causality. However, tasks like generating viral reels for marketing purposes never appealed to me.
Framing generation tasks with goals like efficient content creation or enhanced productivity devalues art. This isn't to say that image or video generation lacks utility or should be avoided. For functional uses, they are quite powerful. I cannot argue against the scale or rapid prototyping they offer. D you need a quick dirty image for a thank you slide? Ask Midjourney immediately. But if you want to cultivate creative thinking, it is best to sit idle and let the mind wander. I may be dismissed as a luddite for these views, but for artistic purposes, we need better tools that are designed to honour human agency. Tools that make us feel closer to reality. Tools that enable us to expand the boundaries of reality.
I'm not addressing the ethical debates here; many artists have written powerfully about it, and I strongly second their views. From an aesthetic standpoint, generated media is too smooth, too sloppy, lacks vibrancy, and importantly, lacks an authorial voice. No, adding "unity" to the prompt won't solve for it. For me, images and videos have layers of meaning that go beyond the realm of textual description.
So, why am I not arguing for the case against text generation? Partly, the reason is tooling. Text-based tools, like ChatGPT, offer a kind of co-creation that image and video modalities don't (yet) enable. I firmly prioritize human agency and authorial voice in the process of creation. When I experience art, I experience the artist's care for me. I feel elated being subject to their compassion and mercy. I believe an artist's personality shows up maximally in the editing process rather than the drafting process. For instance, writerly charm is a consequence of editing text, deleting words, or reconsidering sentence ordering. Ask any creative writer; they'd never take ChatGPT's output verbatim. They'll interact and refine and strongly establish their agency in the final output. This strong collaborative nature ensures creativity isn't fully diminished. On the other hand, if you look at creative support tools in the image domain, they ask for minimal guidance in a different modality (like clicks, text, audio) and over-generate. I hope more research is put in the direction of tools that retain human agency. I explicitly worked towards co-creative colorization in one of my projects at Adobe with this goal.
Richard Zhang, Jun-Yan Zhu, Phillip Isola, Xinyang Geng, Angela S. Lin,
Tianhe Yu, and Alexei A. Efros. 2017. Real-time user-guided image
colorization with learned deep priors. ACM Trans. Graph. 36, 4, Article
119 August (2017).
I loved the framing of colorization as a classification task. Tool
design is also extremely instructive: it invites user's guidance precisely
where ambiguity exists, supporting them through recommendations. The
simulation methods to maintain domain-relevant data, the carefully
constructed experimental questions, and the human evaluation sections are
all a treat to read. I often have trouble thinking about ways to improve
existing methods. All my ideas feel like low-hanging fruits and I struggle
to generate inventiveness that pushes existing methods in non-trivial
ways. I was lucky to discuss this with
Richard Zhang during my time at
Adobe. This work was his second iteration of the colorization task, which
he expanded with a fresh user-guided perspective.
Johnson, Justin, Andrej Karpathy, and Li Fei-Fei. "Densecap: Fully
convolutional localization networks for dense captioning." CVPR
(2016).
Invaluable codebase (in lua!) that still works so well
out-of-the-box. Although captioning capacity has improved over time, I
think this paper's ideas are still relevant and foundational in some
sense. Processing regions and patches with LSTMs reminds me of the VQVAE +
RNN structure used in models like DALL-E today. Even PaLI models have a
similar structure.
Ye, Keren, and Adriana Kovashka. "Advise: Symbolism and external
knowledge for decoding advertisements." ECCV (2018).
This was my introduction to handling large, complex multimodal
datasets and the intricacies they bring. It was also my first experience
following a "paper chain" – where one dataset sparks subsequent
finetuning, tasks, and expansions. Observing how labs build upon each
other's work, exploring tasks from different angles, was a formative
experience. I began to see how research is an ongoing conversation, with
each paper a continuation or challenge to the last, all grounded in a
larger collaborative network.
Guu, Kelvin, et al. "Generating sentences by editing prototypes." TACL
(2018).
This paper introduced me to "edit vectors". I personally feel the
inductive biases here are more compatible with language modelling than
straightfoward next-word prediction. All choices in this work are grounded
in dataset behaviour, making it a great example of examining the data's
predictive capacity before diving into modeling.
Carlini, Nicholas, et al. "Extracting training data from large language
models." 30th USENIX Security Symposium USENIX Security (2021).
Language models memorize data. When can such eidetic memory be
harmful? A smart way to quantify this is by comparing zlib entropy and
gpt-2 perplexity on extracted words. If a word (say, a password) is
surprising but gpt-2 isn't terribly perplexed by it, it means gpt-2 has
memorized it. Figure 3 beautifully illustrates this idea.
Shruti Rijhwani, Antonios Anastasopoulos, and Graham Neubig. "OCR Post
Correction for Endangered Language Texts." EMNLP (2020).
I am quite fond of ML tools that help analyze archival texts. The
real challenge lies in identifying a critical subset of archival data
wherein predictions can help.Here, the choice is a set of old books with
text in an endangered language and corresponding translations in a
high-resource language.
Danish Pruthi, Bhuwan Dhingra, and Zachary C. Lipton. "Combating
Adversarial Misspellings with Robust Word Recognition." ACL (2019).
Three aspects of this paper stand out to me. One, going against
conventional wisdom to show that character LMs are not always better and
their expressivity can hurt. Two, the importance of a backoff model. And
three, a nice word recognition model that incorporates psycholinguistics.
Many have expressed surprise at how quickly students and researchers flocked to this subfield. Until about 2018, it wasn't even taught in standard ML courses. It didn't seem to be a major point of focus until the now-famous king/queen analogy surfaced in word2vec paper in 2014. With so many leaderboards to top, datasets to train on, and competitions like Kaggle to conquer, why did students feel interpretability was the right way to go? There was a related discussion on Twitter recently, which made me reflect on my own path and taste in this subfield.
I don't claim to have a full answer, but I can offer a perspective that might resonate with my generation of researchers. Chris Olah's blog posts, which broke down the inner workings of RNNs and LSTMs, were nothing short of thrilling. He was a cool guy. I was always on the lookout for his work. He then started Distill in 2017, a high-quality open-source publication aimed at reducing scientific and technical debt. Distill posts were equally stunning, evocatively written. and most importantly, they conveyed a sense of moral urgency and philosophical weight. Their metaphor of interpretability as a microscope into neural networks – a tool to uncover hidden mechanisms of the world in ways no prior scientist had – felt revolutionary. Naturally, I, like many others, gravitated toward this world. It felt morally compelling, a sharp contrast to the mechanical pursuit of leaderboard victories, where models are quickly outdone by adversarial attacks.
But I must confess, there was another reason for the allure of interpretability: it felt easier. You didn't need to train large models. No worrying about obscure things like batchnorm or early stopping or dropout. No endless GPU monitoring. All you had to do was observe floating-point values, slice them up, and try to deduce something meaningful. It seemed achievable, even with limited resources. It felt like a meaningful way to contribute to a field that felt so insular and hidden behind gatekept conferences.
As time passed, though, I realized that I hadn't really understood much. The blog posts that seemed to make sense at first often fell apart under deeper scrutiny. They involved clever trickery, and while I don't doubt the tools researchers built or the insights they gained, I now see that they had the context and advantage of training the models they were interpreting. I later also realised that interpretability does require quite a few GPUs! To establish causal relationships or to isolate subnetworks requires intense computational power and sometimes, retraining models altogether. My early assumptions about this field's accessibility were wrong. I concede that my opinions might be outdated or even incorrect given the rapid advances, but I'm specifically referring to my experiences around 2019-2020.
Generating media purely for the sake of it has always felt dull to me. Undoubtedly, image or text generation tasks have immense pedagogical appeal and demand unique technical skills. I can't imagine a course on VAEs without a task to generate binarized MNIST images. Several interesting NLP subtasks like translation, named entity recognition, and others can be partially solved with text generation as the overarching goal. Video generation, in particular, is an extremely challenging and worthwhile task because it requires models to implicitly internalize causality. However, tasks like generating viral reels for marketing purposes never appealed to me.
Framing generation tasks with goals like efficient content creation or enhanced productivity devalues art. This isn't to say that image or video generation lacks utility or should be avoided. For functional uses, they are quite powerful. I cannot argue against the scale or rapid prototyping they offer. D you need a quick dirty image for a thank you slide? Ask Midjourney immediately. But if you want to cultivate creative thinking, it is best to sit idle and let the mind wander. I may be dismissed as a luddite for these views, but for artistic purposes, we need better tools that are designed to honour human agency. Tools that make us feel closer to reality. Tools that enable us to expand the boundaries of reality.
I'm not addressing the ethical debates here; many artists have written powerfully about it, and I strongly second their views. From an aesthetic standpoint, generated media is too smooth, too sloppy, lacks vibrancy, and importantly, lacks an authorial voice. No, adding "unity" to the prompt won't solve for it. For me, images and videos have layers of meaning that go beyond the realm of textual description.
So, why am I not arguing for the case against text generation? Partly, the reason is tooling. Text-based tools, like ChatGPT, offer a kind of co-creation that image and video modalities don't (yet) enable. I firmly prioritize human agency and authorial voice in the process of creation. When I experience art, I experience the artist's care for me. I feel elated being subject to their compassion and mercy. I believe an artist's personality shows up maximally in the editing process rather than the drafting process. For instance, writerly charm is a consequence of editing text, deleting words, or reconsidering sentence ordering. Ask any creative writer; they'd never take ChatGPT's output verbatim. They'll interact and refine and strongly establish their agency in the final output. This strong collaborative nature ensures creativity isn't fully diminished. On the other hand, if you look at creative support tools in the image domain, they ask for minimal guidance in a different modality (like clicks, text, audio) and over-generate. I hope more research is put in the direction of tools that retain human agency. I explicitly worked towards co-creative colorization in one of my projects at Adobe with this goal.
Richard Zhang, Jun-Yan Zhu, Phillip Isola, Xinyang Geng, Angela S. Lin,
Tianhe Yu, and Alexei A. Efros. 2017. Real-time user-guided image
colorization with learned deep priors. ACM Trans. Graph. 36, 4, Article
119 August (2017).
I loved the framing of colorization as a classification task. Tool
design is also extremely instructive: it invites user's guidance precisely
where ambiguity exists, supporting them through recommendations. The
simulation methods to maintain domain-relevant data, the carefully
constructed experimental questions, and the human evaluation sections are
all a treat to read. I often have trouble thinking about ways to improve
existing methods. All my ideas feel like low-hanging fruits and I struggle
to generate inventiveness that pushes existing methods in non-trivial
ways. I was lucky to discuss this with
Richard Zhang during my time at
Adobe. This work was his second iteration of the colorization task, which
he expanded with a fresh user-guided perspective.
Johnson, Justin, Andrej Karpathy, and Li Fei-Fei. "Densecap: Fully
convolutional localization networks for dense captioning." CVPR
(2016).
Invaluable codebase (in lua!) that still works so well
out-of-the-box. Although captioning capacity has improved over time, I
think this paper's ideas are still relevant and foundational in some
sense. Processing regions and patches with LSTMs reminds me of the VQVAE +
RNN structure used in models like DALL-E today. Even PaLI models have a
similar structure.
Ye, Keren, and Adriana Kovashka. "Advise: Symbolism and external
knowledge for decoding advertisements." ECCV (2018).
This was my introduction to handling large, complex multimodal
datasets and the intricacies they bring. It was also my first experience
following a "paper chain" – where one dataset sparks subsequent
finetuning, tasks, and expansions. Observing how labs build upon each
other's work, exploring tasks from different angles, was a formative
experience. I began to see how research is an ongoing conversation, with
each paper a continuation or challenge to the last, all grounded in a
larger collaborative network.
Guu, Kelvin, et al. "Generating sentences by editing prototypes." TACL
(2018).
This paper introduced me to "edit vectors". I personally feel the
inductive biases here are more compatible with language modelling than
straightfoward next-word prediction. All choices in this work are grounded
in dataset behaviour, making it a great example of examining the data's
predictive capacity before diving into modeling.
Carlini, Nicholas, et al. "Extracting training data from large language
models." 30th USENIX Security Symposium USENIX Security (2021).
Language models memorize data. When can such eidetic memory be
harmful? A smart way to quantify this is by comparing zlib entropy and
gpt-2 perplexity on extracted words. If a word (say, a password) is
surprising but gpt-2 isn't terribly perplexed by it, it means gpt-2 has
memorized it. Figure 3 beautifully illustrates this idea.
Shruti Rijhwani, Antonios Anastasopoulos, and Graham Neubig. "OCR Post
Correction for Endangered Language Texts." EMNLP (2020).
I am quite fond of ML tools that help analyze archival texts. The
real challenge lies in identifying a critical subset of archival data
wherein predictions can help.Here, the choice is a set of old books with
text in an endangered language and corresponding translations in a
high-resource language.
Danish Pruthi, Bhuwan Dhingra, and Zachary C. Lipton. "Combating
Adversarial Misspellings with Robust Word Recognition." ACL (2019).
Three aspects of this paper stand out to me. One, going against
conventional wisdom to show that character LMs are not always better and
their expressivity can hurt. Two, the importance of a backoff model. And
three, a nice word recognition model that incorporates psycholinguistics.
Many have expressed surprise at how quickly students and researchers flocked to this subfield. Until about 2018, it wasn't even taught in standard ML courses. It didn't seem to be a major point of focus until the now-famous king/queen analogy surfaced in word2vec paper in 2014. With so many leaderboards to top, datasets to train on, and competitions like Kaggle to conquer, why did students feel interpretability was the right way to go? There was a related discussion on Twitter recently, which made me reflect on my own path and taste in this subfield.
I don't claim to have a full answer, but I can offer a perspective that might resonate with my generation of researchers. Chris Olah's blog posts, which broke down the inner workings of RNNs and LSTMs, were nothing short of thrilling. He was a cool guy. I was always on the lookout for his work. He then started Distill in 2017, a high-quality open-source publication aimed at reducing scientific and technical debt. Distill posts were equally stunning, evocatively written. and most importantly, they conveyed a sense of moral urgency and philosophical weight. Their metaphor of interpretability as a microscope into neural networks – a tool to uncover hidden mechanisms of the world in ways no prior scientist had – felt revolutionary. Naturally, I, like many others, gravitated toward this world. It felt morally compelling, a sharp contrast to the mechanical pursuit of leaderboard victories, where models are quickly outdone by adversarial attacks.
But I must confess, there was another reason for the allure of interpretability: it felt easier. You didn't need to train large models. No worrying about obscure things like batchnorm or early stopping or dropout. No endless GPU monitoring. All you had to do was observe floating-point values, slice them up, and try to deduce something meaningful. It seemed achievable, even with limited resources. It felt like a meaningful way to contribute to a field that felt so insular and hidden behind gatekept conferences.
As time passed, though, I realized that I hadn't really understood much. The blog posts that seemed to make sense at first often fell apart under deeper scrutiny. They involved clever trickery, and while I don't doubt the tools researchers built or the insights they gained, I now see that they had the context and advantage of training the models they were interpreting. I later also realised that interpretability does require quite a few GPUs! To establish causal relationships or to isolate subnetworks requires intense computational power and sometimes, retraining models altogether. My early assumptions about this field's accessibility were wrong. I concede that my opinions might be outdated or even incorrect given the rapid advances, but I'm specifically referring to my experiences around 2019-2020.
Another sobering realization came from the post-hoc nature of much of the work. It feels, at times, like we are doing free labour for bigtech's models. BERTology comes to mind. A microscope to observe and decode nature's underlying mechanisms makes sense, but what's so sacrosanct about the weights of BERT that we spend months staring at them? And, if we indeed interpret that the weights contain harmful biases, does it really make a difference if we pretentiously nullify them? Do the weights not reflect harmful intentions on the model creators' part in a deontological sense?
The cycle of interpreting these large models only to see them soon outclassed by new architectures leaves us scrambling to devise new interpretations. Worse, the suggestions we make for building more interpretable models are often ignored by those creating the large models in the first place. It's as if interpretability serves merely as insurance against the risk of bad model behaviours or as a pretext to scale up rather than a genuine pursuit of understanding. This is why I've grown more drawn to building small and inherently interpretable models: those that integrate sparsity and explicit generative stories from the get-go.
Adversarial ML has its own struggles. Nicholas Carlini recently made caustic remarks on its stagnation. While adversarial examples have been plentiful, real progress in defending against them has been slow. Bias mitigation, too, suffers from ambiguity. What exactly is bias? How do we define and measure it? What does mitigation even mean sociologically, and how can we ever be sure we've mitigated bias fully? Indeed, honest inquiry and a partial solution to these questions is worthwhile, but aren't they too early for an undergrad in tech to think through?
Even the term "explanation" is contested. After all, it's inherently tied to human perception and subjectivity. An explanation that works for me might not strike a chord with you. How can we expect machine learning models to explain things that humans don't fully understand? If explanations were easy, we'd have a 3b1b for every topic in science. Moreover, what if an explanation isn't truly faithful but still manages to garner trust? Mathematically formalizing notions like trust or faithfulness is not only difficult but also risks oversimplifying and glossing over ambiguities.
In retrospect, a combination of Distill's compelling communication, the subfield's moral authority, and students' desire to participate in something beautiful but seemingly low-effort likely fueled the interpretability wave. Don't get me wrong – every subfield has its epistemological disagreements over definitions, methodologies, and directions. This community, to its credit, embraces these debates openly, fostering a sense of intellectual curiosity. But I do think it may have attracted too much energy too quickly. Perhaps this enthusiasm would have been better divided into other areas like dataset curation, model compression, or other foundational advances. It is a nascent subfield that has been growing so fast, and I worry it doesn't have the room to breathe. In a way, it is like a microcosm of the broader issues plaguing the ML community: too many papers, too many spurious conclusions.
I've lost touch with the latest in interpretability. Mechanistic interpretability, in particular, seems to have captured the community's imagination. I haven't engaged with it, nor have I dived into Alignment Forums or LessWrong communities where much of this discourse takes place. I recently came across a critical piece that validated my sense of disconnect. As the authors have expressed, this new cultural obsession with AI Risk feels a bit alien and overreaching to me.
It's a long rant, but it's the only way to process my time in the subfield, where I feel I have little to show except for a few gotchas and some shiny diagrams. Sometimes I think back to an interpretability project from my undergraduate days, wondering if I should've worked on something more technical, like cross-pollinating stochastic blockmodels with VAEs maybe – projects that challenge you pedagogically and force you to learn. That said, I still have a meaningful interest in creating interpretable models that people can actually understand.
I hope my reflections don't come off as dismissive – I have deep respect for the interpretability community and the conversations it fosters. Understanding how these systems work is indeed a noble pursuit. Ultimately, I hope to find a way forward that aligns with both the motivations of the community and my own. I hope, along the way, I will avoid the pathologies from my previous interactions, possibly with a renewed focus on human aspects of interpretability.
Olah, et al., "The Building Blocks of Interpretability". Distill
(2018).
A seminal article that shaped the field, formalizing key
interpretability methods like feature visualization and attribution. Its
visual appeal brought energy to the community. In many ways, it set the
tone for an entire wave of interpretability work. It's a testament to how
aesthetics and quality dissemination guided by technical rigour can shape
the trajectory of a subfield.
Goh, et al., "Multimodal Neurons in Artificial Neural Networks".
Distill (2021).
Again, unmatched aesthetics. Fantastic experiments, especially the
Stroop effect one. Analogies, metaphors, choices all strike a chord. I
might sound fanatical, but even the contributions section is written with
such care and deliberation. It showed me how deeply collaborative research
can be.
Srinivas, Suraj, and François Fleuret. "Rethinking the role of
gradient-based attribution methods for model interpretability." ICLR
(2021).
I love everything about this paper: problem formulation,
methodology, and experiments. Adding a constant function to the output
layer doesn't change predictions but changes attribution. Does it mean
multiple attributions (explanations) exist? What's the best possible
attribution, then? There's a beautiful trick to take the gradients of a
hessian.
Sarah Wiegreffe and Yuval Pinter."Attention is not not Explanation."
EMNLP (2019).
This paper is an excellent example of research communication – how
to disagree with previous work critically, not just express skepticism but
engage constructively and improve. Also a good discussion of what a
faithful explanation is. Should we really be bothered if multiple
attention maps exist?
Arora, Siddhant, et al. "Explain, edit, and understand: Rethinking user
study design for evaluating model explanations." AAAI (2022).
A sobering look at explainability techniques. It turns out several
of these make no difference at the user's end when simulating a model. Why
simulate? Because it feels like the ultimate way to evaluate if users have
understood a model. To add to woes, they show that even a simple
explainable linear classifier trained to mock BERT outperforms exotic
techniques like SHAP.
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav
Goldberg. "Null It Out: Guarding Protected Attributes by Iterative
Nullspace Projection." ACL (2020).
A simple idea for (weak) bias mitigation: figure out a matrix that
projects word embeddings onto the nullspace of a gender classifier. This
removes gender-related information from the embeddings in all directions,
not just along a few hand-picked directions (like *she* vector minus *he*
vector).
Parikh, Devi, and C. Lawrence Zitnick. "Exploring crowd co-creation
scenarios for sketches." ICCC (2020).
Small paper but a useful heuristic of creativity as a combination
of novelty and value. This work stuck with me because it reminds me how
complicated it can be to measure creativity. Automated eval tools simply
don't cut it.
Tal Linzen. "How Can We Accelerate Progress Towards Human-like
Linguistic Generalization?" ACL (2020).
Leaderboards are unfairly skewed towards those with more resources.
We need dynamic, moving evaluations. Otherwise, our models will end up
strongly finetuned to spurious patterns.
Ribeiro, Marco Tulio, et al. "Beyond accuracy: Behavioral testing of
NLP models with CheckList." ACL (2020).
Testing is often treated as unquestionably important and sacred in
an almost tyrannical way. I think testing is indeed important, but it
requires careful integration. Adding tests just for the sake of it would
be a waste of time. Having said that, unit / e2e testing is honestly
underused in ML research, resulting in brittle deployments. I liked the
generation of automated test cases in this paper. It is a rare
demonstration of putting adversarial ML to practical use.
Oore, Sageev, et al. "This time with feeling: Learning expressive
musical performance." Neural Computing and Applications 32 (2020):
955-967.
Though I've never dealt with generative audio modelling (perhaps
because I don't play instruments), this paper remains one of my
favourites. It's lovingly written by the authors. The biggest revelation
for me was the complexity of evaluating music. While models can generate
musical scores (like word tokens), the challenge lies in translating them
into an original, expressive performance. Ideally, an expert musician has
to play the generated score. Next, an expert listener has to dedicatedly
sit through several such scores for evaluation. Recruiting experts is
tedious and prohibitively expensive! We don't see these caveats in image
or text evaluation because seeing and interpreting those modalities comes
to us naturally. Overall, this paper made me appreciate how tricky "real"
evaluation is.
Abigail See, Stephen Roller, Douwe Kiela, and Jason Weston. "What makes
a good conversation? How controllable attributes affect human
judgments." NAACL (2019).
My goto paper to refresh ideas about human evaluation. So
thoughtful and masterfully crafted. I've even explicitly repurposed the
appendix's fboxes in some of my work.
RL has always felt elusive to me. I often start with the basics but lose interest before progressing to modern deep RL, or I dive straight into deep RL without grasping the foundational ideas. This disconnect is probably a consequence of me not following a full-length course so far. Recent tutorials have tried bridging this gap, but RL remains too expansive, blurry, and intimidating pedagogically. It resembles so many things, yet often isn't quite what it appears to be.
I also feel somewhat uncomfortable with RL's reliance on video game-based examples (like Atari). To genuinely grasp a subfield, one needs a healthy obsession with its canonical examples, so its values, cultures, logic, and motivations can resonate. For NLP, a genuine interest in linguistics helps. For edtech, deeply caring for children is paramount to creating effective tools. I, unfortunately, lack interest in robotics or gaming enough to deeply relate to RL's trends.
This isn't to say that evidence of care is absolutely necessary or sufficient to produce wonderful results. Often, a fresh perspective outside the canonical can revitalize a subfield. This is the promise of interdisciplinarity. But it's hard. I do appreciate the trend of improving language models with RL – actions as word tokens feel more inviting to me than game moves in, say, Starcraft.
Consequently, I lean towards supervised or variational approaches to RL – methods that make sense to me given my background. I like seeing RL as an alternating optimization problem: first, optimize for data collection through a variational distribution, then optimize policy model parameters by maximizing the ELBO. When I encounter new RL jargon like expert iteration, behaviour cloning, or off-policy learning (trust me, there are more terms here than params in LLMs), I map it back to this alternating framework. It feels reassuring, but it also nudges me to investigate the subtle differences in each term. Otherwise, the blurry "truthiness" of RL can make the formulation seem obvious, and I risk unconsciously accepting it.
In terms of applicability, I find RL particularly challenging. There are rough guidelines, like using RL when a non-differentiable loss arises, for example. But often, there's little clarity about the kind of data required. What trajectories will work? Say I have 10k trajectories – do I just use off-the-shelf implementations? There are countless ways to view and process these trajectories, and it's rarely obvious which approach fits. The intuitions around data quality/size or model size still feel unclear. Above all, I struggle to tell if a problem is fully specified; sometimes, it feels like a reach to expect RL to do anything meaningful. This sense of ambiguity is pervasive, and I feel people helplessly end up shoehorning problems into PPO.
RL isn't always expensive or complex, and this is where tracing the lineage of today's methods from simple foundational principles helps. A great example is the shift from PPO to DPO for RLHF: by reframing it as a supervised weighted regression problem, we end up with an RL-free algorithm for RLHF. This isn't about rejecting RL altogether; rather, it is a call to think carefully and add complexity only when needed. It reaffirmed my bias toward seeing RL through a supervised lens.
Mirhoseini, Azalia, et al. "A graph placement methodology for fast chip
design." Nature (2021).
I really liked this application of RL in a physical setting for two
reasons: (a) reward shaping guided by domain expertise; (b) transfer
learning across various netlist configurations which could be thought of
as different chess games (with altering rules for pieces!). The analogy
with chess made me think deeper and appreciate the subtle differences. If
it is tricky to learn a single chess game, how come we are learning chip
placement (multiple chess games with differing rules)? Because of the
smaller action space and careful rewards at each step! There is no self
play in the netlist case.
Chen, Lili, et al. "Decision transformer: Reinforcement learning via
sequence modeling." NeurIPS (2021).
A powerful idea illustrated with a simple graph example. Given
thousands of random walk trajectories from a graph, can we predict the
shortest path between two nodes? Yes, and it is a surprise that we can
even pull this off! I generally find supervised RL formulations more
palpable but they are generally seen only in single-step RL cases. Here,
we have an end-to-end supervised model for multi-step RL using
transformers. We get a reward predictor, a next-state predictor, and a
next-action predictor for free! Of course, there is no free lunch; if the
trajectory count is low or trajectories don't explore the space well
enough, we get degenerate outputs.
Carroll, Micah, et al. "On the utility of learning about humans for
human-ai coordination." NeurIPS (2019).
Introduced me to the "Overcooked" environment and multi-agent MDP.
Self-play between two agents doesn't inform them enough about human
actions. What if we constrain one agent's action to mimic a human using
behaviour cloning? Could the other agent learn better? Also, I loved the
design and colours of graphs, and I repurposed the same style in one of my
papers.
Wu, S. A., Wang, R. E., Evans, J. A., Tenenbaum, J. B., Parkes, D. C.,
& Kleiman‐Weiner, M. Too many cooks: Bayesian inference for
coordinating multi‐agent collaboration. Topics in Cognitive Science,
13(2), 414-432. (2021).
Introduced me to "theory-of-mind" and ways for one agent to model
the beliefs of another agent. I found the experiments to be particularly
compelling. Demonstrating an unlikely "collaboration" between agents is a
nice example with powerful implications for future systems. I was inspired
by this work and tried out an extension in one of my projects at Adobe: a
three-agent system with two humans and one learned policy to foster
collaboration between humans.
I'm convinced hardware optimizations play one of the most critical roles in advancing ML research. It's evident everywhere, whether through the bitter lesson or the hardware race in the market. Everyone is chasing GPUs, TPUs, and designing their own hardware compilers like Triton. I haven't spent enough time working through scaling laws, and I suspect I won't in the future either, preferring to rely on the ingenious advancements made by the rest.
That said, my interests do intersect with hardware in specific ways. I gravitate towards low-resource, low-compute solutions – not just for cost-saving reasons but because these approaches fit best in my local context and ethos. Three strategies come to mind, rooted in probabilistic models and principled thinking: one, uncover parallelism and convert matrix multiplications to element-wise multiplications; two, discretize wherever possible; and three, differentiate cleverly. A combination of these approaches can really push the boundaries. I'm always on the lookout for such optimizations. I see JAX as a very promising library for pursuing these directions.
Justin Chiu and Alexander Rush."Scaling Hidden Markov Language Models."
EMNLP (2020).
Blocked emissions to scale up HMM latent state size. I've never
coded in Apache LLVM, though. I read it only out of leisure, and it stuck
with me how smart, precise changes, without compromising on exact
probabilities, can fetch gains in speed, scale, and parallelism.
Hooker, Sara. "The hardware lottery." Communications of the ACM 64.12
(2021).
Quite a famous position paper, which I agree with. We may
potentially be climbing the wrong hill in ML progress. We need to allow
room for experimentation. And that comes with enabling ideas whose
hardware requirements may not align with today's GPU parallelism.
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. 2022. "BitFit:
Simple Parameter-efficient Fine-tuning for Transformer-based Masked
Language-models." ACL (2022).
Smart choice to finetune only the bias terms. This is quite
efficient and achieves comparable performance to full finetuning. This is
especially ideal for low resource settings. The core gain lies in moving
away from matrix multiplication in backprop to element-wise
multiplication.
I dabbled in graphic design with Adobe Illustrator during high school, so I've always had some affinity for SVGs and their strengths, though obviously not in the context of generative modelling. When I joined Adobe and had the chance to think more deeply about these tools, I realized that despite their ubiquity in the design world, SVGs are largely overlooked by the ML community due to two main challenges: rasterization is not differentiable because of its inherent discreteness, and there's a hardly any freely available SVG data to train models on.
I think SVGs are seriously slept on as a modality. Their versatility is unmatched – they scale infinitely, and we can explicitly model shapes and Bézier curves in a controllable way. Most image generation models today need separate training for different image sizes. If we could train an ideal generative model for SVGs, we could create images of any size in a single forward pass with remarkable clarity. Plus, there's an added layer of interpretability, as we can observe how models construct images explicitly, from paths to colour choices.
Of course, this wouldn't work for all images. Photographs with blurry edges and non-vectorizable features wouldn't fit. But in areas like graphic design and game development, there's tremendous potential.
Li, Tzu-Mao, et al. "Differentiable vector graphics rasterization for
editing and learning." ACM Transactions on Graphics (TOG) 39.6
(2020).
This paper came out at a time when I was playing with SVGs, and it
blew me away. A differentiable rasterizer? Wow. It seems too good to be
true even today. And the wizardry here is an artful application of 3D
Leibniz Integration rule. I'm glad to see renewed interest in this work in
recent times, like Sasha's
DiffRast post. As he
points out, differentiation outside standard text/video modalities is
really underexplored in the ML community.
Carlier, Alexandre, et al. "Deepsvg: A hierarchical generative network
for vector graphics animation." NeurIPS (2020).
Contributes a valuable dataset. Also a very good model to tokenize
and process SVG data.
Mehta, Nikhil, Lawrence Carin Duke, and Piyush Rai. "Stochastic
blockmodels meet graph neural networks." ICML (2019).
Precisely the sort of research I aspire to pursue. Succinct
generative story. Interpretable community structure via sparsity in
variational posterior. Learning community count from data instead of
relying on hyperparameters.
Hiippala, Tuomo, et al. "AI2D-RST: A multimodal corpus of 1000 primary
school science diagrams." LREC (2021).
I had the chance to briefly collaborate with Tuomo Hiippala on
applying various GNNs to this complicated multimodal dataset. We couldn't
get sufficient results for publication, but I gained a sense of the
applicability of graph nets. It's painfully difficult to batch graphs for
training!
Compression is one of my favourite applications of ML, not only because of its utility, but also for its immense pedagogical value. ML courses instill fear of overfitting in learners. In this subfield, however, overfitting is celebrated! We want the compression models to fully memorize inputs at train time and reproduce the exact inputs in a lossless manner at test time. Note that LLMs intend to memorize inputs too, just that they are designed to output creative combinations of words (what popular media denigrates as *hallucinations*) rather than exact reconstructions.
I have fond memories of working on an image compression project in Adobe with Kuldeep Kulkarni, a brilliant mentor and friend. The goal was to compress images at multiple bitrates using a single GAN.
Agustsson, Eirikur, et al. "Generative adversarial networks for extreme
learned image compression." ICCV (2019).
Our work was based on this well-written paper. I particularly liked
the user study and Figure 5.
Dupont, Emilien et al. "COIN: COmpression with Implicit Neural
representations." ArXiv abs/2103.03123 (2021).
Overfit a per-instance neural net to each image. During
transmission, instead of passing image pixels, pass the neural net weights
instead! We need not bother about image shapes anymore. Understandably,
the method is super slow, and there are other gaps. But, reading this
paper was revelatory to me. I could clearly see the advantage of neural
nets in compression.
Generating media purely for the sake of it has always felt dull to me. Undoubtedly, image or text generation tasks have immense pedagogical appeal and demand unique technical skills. I can't imagine a course on VAEs without a task to generate binarized MNIST images. Several interesting NLP subtasks like translation, named entity recognition, and others can be partially solved with text generation as the overarching goal. Video generation, in particular, is an extremely challenging and worthwhile task because it requires models to implicitly internalize causality. However, tasks like generating viral reels for marketing purposes never appealed to me.
Framing generation tasks with goals like efficient content creation or enhanced productivity devalues art. This isn't to say that image or video generation lacks utility or should be avoided. For functional uses, they are quite powerful. I cannot argue against the scale or rapid prototyping they offer. D you need a quick dirty image for a thank you slide? Ask Midjourney immediately. But if you want to cultivate creative thinking, it is best to sit idle and let the mind wander. I may be dismissed as a luddite for these views, but for artistic purposes, we need better tools that are designed to honour human agency. Tools that make us feel closer to reality. Tools that enable us to expand the boundaries of reality.
I'm not addressing the ethical debates here; many artists have written powerfully about it, and I strongly second their views. From an aesthetic standpoint, generated media is too smooth, too sloppy, lacks vibrancy, and importantly, lacks an authorial voice. No, adding "unity" to the prompt won't solve for it. For me, images and videos have layers of meaning that go beyond the realm of textual description.
So, why am I not arguing for the case against text generation? Partly, the reason is tooling. Text-based tools, like ChatGPT, offer a kind of co-creation that image and video modalities don't (yet) enable. I firmly prioritize human agency and authorial voice in the process of creation. When I experience art, I experience the artist's care for me. I feel elated being subject to their compassion and mercy. I believe an artist's personality shows up maximally in the editing process rather than the drafting process. For instance, writerly charm is a consequence of editing text, deleting words, or reconsidering sentence ordering. Ask any creative writer; they'd never take ChatGPT's output verbatim. They'll interact and refine and strongly establish their agency in the final output. This strong collaborative nature ensures creativity isn't fully diminished. On the other hand, if you look at creative support tools in the image domain, they ask for minimal guidance in a different modality (like clicks, text, audio) and over-generate. I hope more research is put in the direction of tools that retain human agency. I explicitly worked towards co-creative colorization in one of my projects at Adobe with this goal.
Richard Zhang, Jun-Yan Zhu, Phillip Isola, Xinyang Geng, Angela S. Lin,
Tianhe Yu, and Alexei A. Efros. 2017. Real-time user-guided image
colorization with learned deep priors. ACM Trans. Graph. 36, 4, Article
119 August (2017).
I loved the framing of colorization as a classification task. Tool
design is also extremely instructive: it invites user's guidance precisely
where ambiguity exists, supporting them through recommendations. The
simulation methods to maintain domain-relevant data, the carefully
constructed experimental questions, and the human evaluation sections are
all a treat to read. I often have trouble thinking about ways to improve
existing methods. All my ideas feel like low-hanging fruits and I struggle
to generate inventiveness that pushes existing methods in non-trivial
ways. I was lucky to discuss this with
Richard Zhang during my time at
Adobe. This work was his second iteration of the colorization task, which
he expanded with a fresh user-guided perspective.
Johnson, Justin, Andrej Karpathy, and Li Fei-Fei. "Densecap: Fully
convolutional localization networks for dense captioning." CVPR
(2016).
Invaluable codebase (in lua!) that still works so well
out-of-the-box. Although captioning capacity has improved over time, I
think this paper's ideas are still relevant and foundational in some
sense. Processing regions and patches with LSTMs reminds me of the VQVAE +
RNN structure used in models like DALL-E today. Even PaLI models have a
similar structure.
Ye, Keren, and Adriana Kovashka. "Advise: Symbolism and external
knowledge for decoding advertisements." ECCV (2018).
This was my introduction to handling large, complex multimodal
datasets and the intricacies they bring. It was also my first experience
following a "paper chain" – where one dataset sparks subsequent
finetuning, tasks, and expansions. Observing how labs build upon each
other's work, exploring tasks from different angles, was a formative
experience. I began to see how research is an ongoing conversation, with
each paper a continuation or challenge to the last, all grounded in a
larger collaborative network.
Guu, Kelvin, et al. "Generating sentences by editing prototypes." TACL
(2018).
This paper introduced me to "edit vectors". I personally feel the
inductive biases here are more compatible with language modelling than
straightfoward next-word prediction. All choices in this work are grounded
in dataset behaviour, making it a great example of examining the data's
predictive capacity before diving into modeling.
Carlini, Nicholas, et al. "Extracting training data from large language
models." 30th USENIX Security Symposium USENIX Security (2021).
Language models memorize data. When can such eidetic memory be
harmful? A smart way to quantify this is by comparing zlib entropy and
gpt-2 perplexity on extracted words. If a word (say, a password) is
surprising but gpt-2 isn't terribly perplexed by it, it means gpt-2 has
memorized it. Figure 3 beautifully illustrates this idea.
Shruti Rijhwani, Antonios Anastasopoulos, and Graham Neubig. "OCR Post
Correction for Endangered Language Texts." EMNLP (2020).
I am quite fond of ML tools that help analyze archival texts. The
real challenge lies in identifying a critical subset of archival data
wherein predictions can help.Here, the choice is a set of old books with
text in an endangered language and corresponding translations in a
high-resource language.
Danish Pruthi, Bhuwan Dhingra, and Zachary C. Lipton. "Combating
Adversarial Misspellings with Robust Word Recognition." ACL (2019).
Three aspects of this paper stand out to me. One, going against
conventional wisdom to show that character LMs are not always better and
their expressivity can hurt. Two, the importance of a backoff model. And
three, a nice word recognition model that incorporates psycholinguistics.
Many have expressed surprise at how quickly students and researchers flocked to this subfield. Until about 2018, it wasn't even taught in standard ML courses. It didn't seem to be a major point of focus until the now-famous king/queen analogy surfaced in word2vec paper in 2014. With so many leaderboards to top, datasets to train on, and competitions like Kaggle to conquer, why did students feel interpretability was the right way to go? There was a related discussion on Twitter recently, which made me reflect on my own path and taste in this subfield.
I don't claim to have a full answer, but I can offer a perspective that might resonate with my generation of researchers. Chris Olah's blog posts, which broke down the inner workings of RNNs and LSTMs, were nothing short of thrilling. He was a cool guy. I was always on the lookout for his work. He then started Distill in 2017, a high-quality open-source publication aimed at reducing scientific and technical debt. Distill posts were equally stunning, evocatively written. and most importantly, they conveyed a sense of moral urgency and philosophical weight. Their metaphor of interpretability as a microscope into neural networks – a tool to uncover hidden mechanisms of the world in ways no prior scientist had – felt revolutionary. Naturally, I, like many others, gravitated toward this world. It felt morally compelling, a sharp contrast to the mechanical pursuit of leaderboard victories, where models are quickly outdone by adversarial attacks.
But I must confess, there was another reason for the allure of interpretability: it felt easier. You didn't need to train large models. No worrying about obscure things like batchnorm or early stopping or dropout. No endless GPU monitoring. All you had to do was observe floating-point values, slice them up, and try to deduce something meaningful. It seemed achievable, even with limited resources. It felt like a meaningful way to contribute to a field that felt so insular and hidden behind gatekept conferences.
As time passed, though, I realized that I hadn't really understood much. The blog posts that seemed to make sense at first often fell apart under deeper scrutiny. They involved clever trickery, and while I don't doubt the tools researchers built or the insights they gained, I now see that they had the context and advantage of training the models they were interpreting. I later also realised that interpretability does require quite a few GPUs! To establish causal relationships or to isolate subnetworks requires intense computational power and sometimes, retraining models altogether. My early assumptions about this field's accessibility were wrong. I concede that my opinions might be outdated or even incorrect given the rapid advances, but I'm specifically referring to my experiences around 2019-2020.
Another sobering realization came from the post-hoc nature of much of the work. It feels, at times, like we are doing free labour for bigtech's models. BERTology comes to mind. A microscope to observe and decode nature's underlying mechanisms makes sense, but what's so sacrosanct about the weights of BERT that we spend months staring at them? And, if we indeed interpret that the weights contain harmful biases, does it really make a difference if we pretentiously nullify them? Do the weights not reflect harmful intentions on the model creators' part in a deontological sense?
The cycle of interpreting these large models only to see them soon outclassed by new architectures leaves us scrambling to devise new interpretations. Worse, the suggestions we make for building more interpretable models are often ignored by those creating the large models in the first place. It's as if interpretability serves merely as insurance against the risk of bad model behaviours or as a pretext to scale up rather than a genuine pursuit of understanding. This is why I've grown more drawn to building small and inherently interpretable models: those that integrate sparsity and explicit generative stories from the get-go.
Adversarial ML has its own struggles. Nicholas Carlini recently made caustic remarks on its stagnation. While adversarial examples have been plentiful, real progress in defending against them has been slow. Bias mitigation, too, suffers from ambiguity. What exactly is bias? How do we define and measure it? What does mitigation even mean sociologically, and how can we ever be sure we've mitigated bias fully? Indeed, honest inquiry and a partial solution to these questions is worthwhile, but aren't they too early for an undergrad in tech to think through?
Even the term "explanation" is contested. After all, it's inherently tied to human perception and subjectivity. An explanation that works for me might not strike a chord with you. How can we expect machine learning models to explain things that humans don't fully understand? If explanations were easy, we'd have a 3b1b for every topic in science. Moreover, what if an explanation isn't truly faithful but still manages to garner trust? Mathematically formalizing notions like trust or faithfulness is not only difficult but also risks oversimplifying and glossing over ambiguities.
In retrospect, a combination of Distill's compelling communication, the subfield's moral authority, and students' desire to participate in something beautiful but seemingly low-effort likely fueled the interpretability wave. Don't get me wrong – every subfield has its epistemological disagreements over definitions, methodologies, and directions. This community, to its credit, embraces these debates openly, fostering a sense of intellectual curiosity. But I do think it may have attracted too much energy too quickly. Perhaps this enthusiasm would have been better divided into other areas like dataset curation, model compression, or other foundational advances. It is a nascent subfield that has been growing so fast, and I worry it doesn't have the room to breathe. In a way, it is like a microcosm of the broader issues plaguing the ML community: too many papers, too many spurious conclusions.
I've lost touch with the latest in interpretability. Mechanistic interpretability, in particular, seems to have captured the community's imagination. I haven't engaged with it, nor have I dived into Alignment Forums or LessWrong communities where much of this discourse takes place. I recently came across a critical piece that validated my sense of disconnect. As the authors have expressed, this new cultural obsession with AI Risk feels a bit alien and overreaching to me.
It's a long rant, but it's the only way to process my time in the subfield, where I feel I have little to show except for a few gotchas and some shiny diagrams. Sometimes I think back to an interpretability project from my undergraduate days, wondering if I should've worked on something more technical, like cross-pollinating stochastic blockmodels with VAEs maybe – projects that challenge you pedagogically and force you to learn. That said, I still have a meaningful interest in creating interpretable models that people can actually understand.
I hope my reflections don't come off as dismissive – I have deep respect for the interpretability community and the conversations it fosters. Understanding how these systems work is indeed a noble pursuit. Ultimately, I hope to find a way forward that aligns with both the motivations of the community and my own. I hope, along the way, I will avoid the pathologies from my previous interactions, possibly with a renewed focus on human aspects of interpretability.
Olah, et al., "The Building Blocks of Interpretability". Distill
(2018).
A seminal article that shaped the field, formalizing key
interpretability methods like feature visualization and attribution. Its
visual appeal brought energy to the community. In many ways, it set the
tone for an entire wave of interpretability work. It's a testament to how
aesthetics and quality dissemination guided by technical rigour can shape
the trajectory of a subfield.
Goh, et al., "Multimodal Neurons in Artificial Neural Networks".
Distill (2021).
Again, unmatched aesthetics. Fantastic experiments, especially the
Stroop effect one. Analogies, metaphors, choices all strike a chord. I
might sound fanatical, but even the contributions section is written with
such care and deliberation. It showed me how deeply collaborative research
can be.
Srinivas, Suraj, and François Fleuret. "Rethinking the role of
gradient-based attribution methods for model interpretability." ICLR
(2021).
I love everything about this paper: problem formulation,
methodology, and experiments. Adding a constant function to the output
layer doesn't change predictions but changes attribution. Does it mean
multiple attributions (explanations) exist? What's the best possible
attribution, then? There's a beautiful trick to take the gradients of a
hessian.
Sarah Wiegreffe and Yuval Pinter."Attention is not not Explanation."
EMNLP (2019).
This paper is an excellent example of research communication – how
to disagree with previous work critically, not just express skepticism but
engage constructively and improve. Also a good discussion of what a
faithful explanation is. Should we really be bothered if multiple
attention maps exist?
Arora, Siddhant, et al. "Explain, edit, and understand: Rethinking user
study design for evaluating model explanations." AAAI (2022).
A sobering look at explainability techniques. It turns out several
of these make no difference at the user's end when simulating a model. Why
simulate? Because it feels like the ultimate way to evaluate if users have
understood a model. To add to woes, they show that even a simple
explainable linear classifier trained to mock BERT outperforms exotic
techniques like SHAP.
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav
Goldberg. "Null It Out: Guarding Protected Attributes by Iterative
Nullspace Projection." ACL (2020).
A simple idea for (weak) bias mitigation: figure out a matrix that
projects word embeddings onto the nullspace of a gender classifier. This
removes gender-related information from the embeddings in all directions,
not just along a few hand-picked directions (like *she* vector minus *he*
vector).
Parikh, Devi, and C. Lawrence Zitnick. "Exploring crowd co-creation
scenarios for sketches." ICCC (2020).
Small paper but a useful heuristic of creativity as a combination
of novelty and value. This work stuck with me because it reminds me how
complicated it can be to measure creativity. Automated eval tools simply
don't cut it.
Tal Linzen. "How Can We Accelerate Progress Towards Human-like
Linguistic Generalization?" ACL (2020).
Leaderboards are unfairly skewed towards those with more resources.
We need dynamic, moving evaluations. Otherwise, our models will end up
strongly finetuned to spurious patterns.
Ribeiro, Marco Tulio, et al. "Beyond accuracy: Behavioral testing of
NLP models with CheckList." ACL (2020).
Testing is often treated as unquestionably important and sacred in
an almost tyrannical way. I think testing is indeed important, but it
requires careful integration. Adding tests just for the sake of it would
be a waste of time. Having said that, unit / e2e testing is honestly
underused in ML research, resulting in brittle deployments. I liked the
generation of automated test cases in this paper. It is a rare
demonstration of putting adversarial ML to practical use.
Oore, Sageev, et al. "This time with feeling: Learning expressive
musical performance." Neural Computing and Applications 32 (2020):
955-967.
Though I've never dealt with generative audio modelling (perhaps
because I don't play instruments), this paper remains one of my
favourites. It's lovingly written by the authors. The biggest revelation
for me was the complexity of evaluating music. While models can generate
musical scores (like word tokens), the challenge lies in translating them
into an original, expressive performance. Ideally, an expert musician has
to play the generated score. Next, an expert listener has to dedicatedly
sit through several such scores for evaluation. Recruiting experts is
tedious and prohibitively expensive! We don't see these caveats in image
or text evaluation because seeing and interpreting those modalities comes
to us naturally. Overall, this paper made me appreciate how tricky "real"
evaluation is.
Abigail See, Stephen Roller, Douwe Kiela, and Jason Weston. "What makes
a good conversation? How controllable attributes affect human
judgments." NAACL (2019).
My goto paper to refresh ideas about human evaluation. So
thoughtful and masterfully crafted. I've even explicitly repurposed the
appendix's fboxes in some of my work.
RL has always felt elusive to me. I often start with the basics but lose interest before progressing to modern deep RL, or I dive straight into deep RL without grasping the foundational ideas. This disconnect is probably a consequence of me not following a full-length course so far. Recent tutorials have tried bridging this gap, but RL remains too expansive, blurry, and intimidating pedagogically. It resembles so many things, yet often isn't quite what it appears to be.
I also feel somewhat uncomfortable with RL's reliance on video game-based examples (like Atari). To genuinely grasp a subfield, one needs a healthy obsession with its canonical examples, so its values, cultures, logic, and motivations can resonate. For NLP, a genuine interest in linguistics helps. For edtech, deeply caring for children is paramount to creating effective tools. I, unfortunately, lack interest in robotics or gaming enough to deeply relate to RL's trends.
This isn't to say that evidence of care is absolutely necessary or sufficient to produce wonderful results. Often, a fresh perspective outside the canonical can revitalize a subfield. This is the promise of interdisciplinarity. But it's hard. I do appreciate the trend of improving language models with RL – actions as word tokens feel more inviting to me than game moves in, say, Starcraft.
Consequently, I lean towards supervised or variational approaches to RL – methods that make sense to me given my background. I like seeing RL as an alternating optimization problem: first, optimize for data collection through a variational distribution, then optimize policy model parameters by maximizing the ELBO. When I encounter new RL jargon like expert iteration, behaviour cloning, or off-policy learning (trust me, there are more terms here than params in LLMs), I map it back to this alternating framework. It feels reassuring, but it also nudges me to investigate the subtle differences in each term. Otherwise, the blurry "truthiness" of RL can make the formulation seem obvious, and I risk unconsciously accepting it.
In terms of applicability, I find RL particularly challenging. There are rough guidelines, like using RL when a non-differentiable loss arises, for example. But often, there's little clarity about the kind of data required. What trajectories will work? Say I have 10k trajectories – do I just use off-the-shelf implementations? There are countless ways to view and process these trajectories, and it's rarely obvious which approach fits. The intuitions around data quality/size or model size still feel unclear. Above all, I struggle to tell if a problem is fully specified; sometimes, it feels like a reach to expect RL to do anything meaningful. This sense of ambiguity is pervasive, and I feel people helplessly end up shoehorning problems into PPO.
RL isn't always expensive or complex, and this is where tracing the lineage of today's methods from simple foundational principles helps. A great example is the shift from PPO to DPO for RLHF: by reframing it as a supervised weighted regression problem, we end up with an RL-free algorithm for RLHF. This isn't about rejecting RL altogether; rather, it is a call to think carefully and add complexity only when needed. It reaffirmed my bias toward seeing RL through a supervised lens.
Mirhoseini, Azalia, et al. "A graph placement methodology for fast chip
design." Nature (2021).
I really liked this application of RL in a physical setting for two
reasons: (a) reward shaping guided by domain expertise; (b) transfer
learning across various netlist configurations which could be thought of
as different chess games (with altering rules for pieces!). The analogy
with chess made me think deeper and appreciate the subtle differences. If
it is tricky to learn a single chess game, how come we are learning chip
placement (multiple chess games with differing rules)? Because of the
smaller action space and careful rewards at each step! There is no self
play in the netlist case.
Chen, Lili, et al. "Decision transformer: Reinforcement learning via
sequence modeling." NeurIPS (2021).
A powerful idea illustrated with a simple graph example. Given
thousands of random walk trajectories from a graph, can we predict the
shortest path between two nodes? Yes, and it is a surprise that we can
even pull this off! I generally find supervised RL formulations more
palpable but they are generally seen only in single-step RL cases. Here,
we have an end-to-end supervised model for multi-step RL using
transformers. We get a reward predictor, a next-state predictor, and a
next-action predictor for free! Of course, there is no free lunch; if the
trajectory count is low or trajectories don't explore the space well
enough, we get degenerate outputs.
Carroll, Micah, et al. "On the utility of learning about humans for
human-ai coordination." NeurIPS (2019).
Introduced me to the "Overcooked" environment and multi-agent MDP.
Self-play between two agents doesn't inform them enough about human
actions. What if we constrain one agent's action to mimic a human using
behaviour cloning? Could the other agent learn better? Also, I loved the
design and colours of graphs, and I repurposed the same style in one of my
papers.
Wu, S. A., Wang, R. E., Evans, J. A., Tenenbaum, J. B., Parkes, D. C.,
& Kleiman‐Weiner, M. Too many cooks: Bayesian inference for
coordinating multi‐agent collaboration. Topics in Cognitive Science,
13(2), 414-432. (2021).
Introduced me to "theory-of-mind" and ways for one agent to model
the beliefs of another agent. I found the experiments to be particularly
compelling. Demonstrating an unlikely "collaboration" between agents is a
nice example with powerful implications for future systems. I was inspired
by this work and tried out an extension in one of my projects at Adobe: a
three-agent system with two humans and one learned policy to foster
collaboration between humans.
I'm convinced hardware optimizations play one of the most critical roles in advancing ML research. It's evident everywhere, whether through the bitter lesson or the hardware race in the market. Everyone is chasing GPUs, TPUs, and designing their own hardware compilers like Triton. I haven't spent enough time working through scaling laws, and I suspect I won't in the future either, preferring to rely on the ingenious advancements made by the rest.
That said, my interests do intersect with hardware in specific ways. I gravitate towards low-resource, low-compute solutions – not just for cost-saving reasons but because these approaches fit best in my local context and ethos. Three strategies come to mind, rooted in probabilistic models and principled thinking: one, uncover parallelism and convert matrix multiplications to element-wise multiplications; two, discretize wherever possible; and three, differentiate cleverly. A combination of these approaches can really push the boundaries. I'm always on the lookout for such optimizations. I see JAX as a very promising library for pursuing these directions.
Justin Chiu and Alexander Rush."Scaling Hidden Markov Language Models."
EMNLP (2020).
Blocked emissions to scale up HMM latent state size. I've never
coded in Apache LLVM, though. I read it only out of leisure, and it stuck
with me how smart, precise changes, without compromising on exact
probabilities, can fetch gains in speed, scale, and parallelism.
Hooker, Sara. "The hardware lottery." Communications of the ACM 64.12
(2021).
Quite a famous position paper, which I agree with. We may
potentially be climbing the wrong hill in ML progress. We need to allow
room for experimentation. And that comes with enabling ideas whose
hardware requirements may not align with today's GPU parallelism.
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. 2022. "BitFit:
Simple Parameter-efficient Fine-tuning for Transformer-based Masked
Language-models." ACL (2022).
Smart choice to finetune only the bias terms. This is quite
efficient and achieves comparable performance to full finetuning. This is
especially ideal for low resource settings. The core gain lies in moving
away from matrix multiplication in backprop to element-wise
multiplication.
I dabbled in graphic design with Adobe Illustrator during high school, so I've always had some affinity for SVGs and their strengths, though obviously not in the context of generative modelling. When I joined Adobe and had the chance to think more deeply about these tools, I realized that despite their ubiquity in the design world, SVGs are largely overlooked by the ML community due to two main challenges: rasterization is not differentiable because of its inherent discreteness, and there's a hardly any freely available SVG data to train models on.
I think SVGs are seriously slept on as a modality. Their versatility is unmatched – they scale infinitely, and we can explicitly model shapes and Bézier curves in a controllable way. Most image generation models today need separate training for different image sizes. If we could train an ideal generative model for SVGs, we could create images of any size in a single forward pass with remarkable clarity. Plus, there's an added layer of interpretability, as we can observe how models construct images explicitly, from paths to colour choices.
Of course, this wouldn't work for all images. Photographs with blurry edges and non-vectorizable features wouldn't fit. But in areas like graphic design and game development, there's tremendous potential.
Li, Tzu-Mao, et al. "Differentiable vector graphics rasterization for
editing and learning." ACM Transactions on Graphics (TOG) 39.6
(2020).
This paper came out at a time when I was playing with SVGs, and it
blew me away. A differentiable rasterizer? Wow. It seems too good to be
true even today. And the wizardry here is an artful application of 3D
Leibniz Integration rule. I'm glad to see renewed interest in this work in
recent times, like Sasha's
DiffRast post. As he
points out, differentiation outside standard text/video modalities is
really underexplored in the ML community.
Carlier, Alexandre, et al. "Deepsvg: A hierarchical generative network
for vector graphics animation." NeurIPS (2020).
Contributes a valuable dataset. Also a very good model to tokenize
and process SVG data.
Mehta, Nikhil, Lawrence Carin Duke, and Piyush Rai. "Stochastic
blockmodels meet graph neural networks." ICML (2019).
Precisely the sort of research I aspire to pursue. Succinct
generative story. Interpretable community structure via sparsity in
variational posterior. Learning community count from data instead of
relying on hyperparameters.
Hiippala, Tuomo, et al. "AI2D-RST: A multimodal corpus of 1000 primary
school science diagrams." LREC (2021).
I had the chance to briefly collaborate with Tuomo Hiippala on
applying various GNNs to this complicated multimodal dataset. We couldn't
get sufficient results for publication, but I gained a sense of the
applicability of graph nets. It's painfully difficult to batch graphs for
training!
Compression is one of my favourite applications of ML, not only because of its utility, but also for its immense pedagogical value. ML courses instill fear of overfitting in learners. In this subfield, however, overfitting is celebrated! We want the compression models to fully memorize inputs at train time and reproduce the exact inputs in a lossless manner at test time. Note that LLMs intend to memorize inputs too, just that they are designed to output creative combinations of words (what popular media denigrates as *hallucinations*) rather than exact reconstructions.
I have fond memories of working on an image compression project in Adobe with Kuldeep Kulkarni, a brilliant mentor and friend. The goal was to compress images at multiple bitrates using a single GAN.
Agustsson, Eirikur, et al. "Generative adversarial networks for extreme
learned image compression." ICCV (2019).
Our work was based on this well-written paper. I particularly liked
the user study and Figure 5.
Dupont, Emilien et al. "COIN: COmpression with Implicit Neural
representations." ArXiv abs/2103.03123 (2021).
Overfit a per-instance neural net to each image. During
transmission, instead of passing image pixels, pass the neural net weights
instead! We need not bother about image shapes anymore. Understandably,
the method is super slow, and there are other gaps. But, reading this
paper was revelatory to me. I could clearly see the advantage of neural
nets in compression.
I regret engaging only minimally with ideas in causal inference. I
remember using the term "causal" rather casually in one of my previous
papers, without fully grasping its significance. At the time, I struggled
to find good explanatory resources on the topic. Moreover, whatever little
material I found was tied to economics literature, which isn't a field I
have much taste for. Over the years, I've found better lecture sets, but I
haven't yet had the time to dive into them deeply. Causal inference is
something I plan to dedicate significant time to in the coming years, as
it's particularly relevant for experimental design.
Pearl, Judea.
"The art and science of cause and effect." UCLA Faculty Research Program
Lecture (1996).
Judea Pearl sheds light on why many scientists get
frustrated with causality. It's tough to measure, and it's futile too,
since we likely cannot intervene in natural processes. Yet, he convinced
me that causal arrow diagrams are indispensable in scientific inquiry.
McElreath, Richard. "Statistical Rethinking: A Bayesian course with
examples in R and Stan." Chapman and Hall/CRC, (2018).
Although I still haven't wrapped my head around the final chapters
on instrumental variables, McElreath's breakdown of the four types of
causality, along with the "causal salad" metaphor, resonated with me. The
problem sets have also been incredibly useful for solidifying my
understanding. McElreath is an
incredible teacher. He never misses an opportunity to warn us of the
epistemological limits of statistics..
von Kügelgen, Julius, Luigi Gresele, and Bernhard Schölkopf. "Simpson's
paradox in Covid-19 case fatality rates: a mediation analysis of
age-related causal effects." IEEE Transactions on Artificial
Intelligence 2.1 (2021).
The thing with causal inference is that it makes intuitive sense
diagrammatically. But it's unclear how one actually computes the effects
involved. This paper has an outstanding example with explicit computations
for causal mediation analysis.
Vig, Jesse, et al. "Investigating gender bias in language models using
causal mediation analysis." NeurIPS (2020).
Causal mediation analysis in the context of neural networks. What's
interesting is that sociological concepts like gender bias can have
micro-effects, which are tricky to measure.
I'd like my work to communicate a personality that feels authentic to who I am. Personality is not just a function of our inner selves but also depends on who our audience is. I am often pointed toward human psychology papers to improve on this front. Honestly, I find most psychology studies woefully annoying. I worry about their replicability, and the attempts at diversity also feel contrived and inadequate. Maybe I'm wrong. Maybe I should only seek qualitative insights from them rather than searching for methodological clarity.
Hohman, et al., "Communicating with Interactive Articles", Distill
(2020).
Producing quality blogs is tough and thankless. It can give the
reader an illusion of understanding without translating concretely into
memory.
Conlen, Matthew and Jeffrey Heer. "Fidyll: A Compiler for Cross-Format
Data Stories & Explorable Explanations." ArXiv abs/2205.09858
(2022).
I participated in formative interviews for this paper and vented
about how frustrating it is to create diagrams. I remember spending days
on a figure for a paper, only to have it go unnoticed by reviewers and
peers. I was dejected. Perhaps art is about showing care, trusting that
your audience will, at some point, notice? Our academic standards stifle
creativity too, leaving no scope for exploration. One rule I particularly
dislike: "Don't leave empty space in a paper!" Why not allow some
breathing room?
Grant Sanderson. "Math's pedagogical curse." (2023).
Video.
This talk is a good synthesis of 3b1b's ideas on exposition. Do not
deride rigour. Do not glorify it either in an uninviting manner. Instead,
use rigour to code pedagogically sharp imagery.
Elliot Kenzle. "Manifesting Mathematical Worlds in Digital Art."
(2024).
Video.
Math should glow. Research should glow. Glow aesthetically. Glow
thematically. Glow within us. Glow around us.
This is a topic that often gets overlooked by researchers, yet it's crucial, especially in low-resource settings. During my time at Adobe, I made it a point to prioritize how deployments are surfaced to users. I feel the ML community is stuck in chat-like interfaces while there's so much potential to explore more innovative, lightweight designs. In fact, it is interesting to consider interface design as part of the learning pipeline instead of pushing it to a post-hoc concern at the last moment.
Manu Chopra, Indrani Medhi Thies, Joyojeet Pal, Colin Scott, William
Thies, and Vivek Seshadri. "Exploring Crowdsourced Work in Low-Resource
Settings." CHI (2019).
This paper, connected to Project Karya, has an intriguing interface
for collecting data in low-resource languages. I'm unsure where Project
Karya stands today; some praise its usefulness, while others see it as
being forced by large organizations like the Gates Foundation. A mixed
bag, perhaps, but a fascinating journey from a paper to a dedicated NGO
tool.
Raphael Tang, Jaejun Lee, Afsaneh Razi, Julia Cambre, Ian Bicking,
Jofish Kaye, and Jimmy Lin. "Howl: A Deployed, Open-Source Wake Word
Detection System". NLP-OSS (2020).
Probably the first AI browser tool I had come across that didn't
feel dodgy. It is a lightweight deployment that works efficiently on the
client side. No data is sent to centralized servers. Privacy preserving.
How cool!
Aman Dalmia, Jerome White, Ankit Chaurasia, Vishal Agarwal, Rajesh
Jain, Dhruvin Vora, Balasaheb Dhame, Raghu Dharmaraju, and Rahul
Panicker. "Pest Management In Cotton Farms: An AI-System Case Study from
the Global South." KDD (2020).
Emphasis on offline mobile AI apps, how to work within the
constraints of rural environments, and how to tap into rural community
networks. This paper introduced me to
Aman, a good friend and a
mentor.
Kiri L. Wagstaff. 2012. "Machine learning that matters." ICML
(2012).
Prescient piece, predating the deep learning boom, emphasizing the
importance of applying ML beyond academic datasets like Iris. It stresses
the need to provide clear directions for real-world applications instead
of assuming that others will eventually make well-meaning extensions.
Metcalf, Jacob & Moss, Emanuel & Boyd, Danah. "Owning Ethics:
Corporate Logics, Silicon Valley, and the Institutionalization of
Ethics." Social Research. 86. 449-476. (2019).
Introduced me to concepts like technosolutionism and Silicon
Valley's power to control ethical discourse. Taught me to gauge the limits
of technology.
Rediet Abebe, Solon Barocas, Jon Kleinberg, Karen Levy, Manish
Raghavan, and David G. Robinson. "Roles for computing in social change."
FAccT (2020).
A major clarifier for me and a rubric I often fall back on when
facing moral quandaries. I especially find the formalism idea powerful –
how every mathematical function is partly imbibed with political will.
Broderick T, Gelman A, Meager R, Smith AL, Zheng T. "Toward a taxonomy
of trust for probabilistic machine learning." Sci Adv. (2023).
The flowchart in this paper is a comprehensive account of how
technical/moral failures cascade through the entire modelling process.
I've been more careful while making data collection assumptions since
reading it.
Azra Ismail and Neha Kumar. "AI in Global Health: The View from the
Front Lines." CHI (2021).
An exhaustive ethnographic study at the intersection of technology
and government. What implications can future AI have on already-distressed
ASHA workers? I've suggested this paper to my peers countless times.
Nithya Sambasivan, Erin Arnesen, Ben Hutchinson, Tulsee Doshi, and
Vinodkumar Prabhakaran. 2021. "Re-imagining Algorithmic Fairness in
India and Beyond." (FAccT '21).
Highlights the "machine learner gap" between Western and Eastern
perspectives on fairness. It is not just a difference in time but also in
thought.
Melanie Mitchell. 2021. "Why AI is harder than we think." GECCO
(2021).
A valuable reminder to avoid overconfidence in AI predictions.
Introduced me to the perils of anthropomorphizing AI systems. It was also
the first time I read a historical perspective on AI's challenges.
Samuel Bowman. "The Dangers of Underclaiming: Reasons for Caution When
Reporting How NLP Systems Fail." ACL (2022).
Blind optimism in AI is not good. At the same time, extreme
negativity could hurt us. It encourages complacency, rendering us
unprepared for potentially harmful future advances.
I'll end this section with some unstructured reflections. I understand the need for polemics and strong criticism, especially given the uneven power dynamics in AI, but a well-meaning dialogue with technologists could probably lead to more thoughtful outcomes. I'm not advocating for meek compromises in a bid to sustain the momentum of progress. Some situations do demand de-escalation and a search for new equilibria rather than attempting balance.
But critique shouldn't come from a place of condescension. We don't automatically become better people by forcefully adopting morally just positions. There are, in fact, multiple ways to be morally correct: some idle, some more imaginative. Inaction may feel like a safe, even harmonious choice. A good critique should instead inspire radical action – something new, creative, and challenging. Ethics literature is sadly replete with rubrics, rules, and checklists that leave little room for imagination.
Historically, radical actions have often been contrarian, defying both logic and morality at first. They go against the tide, irritate us, and ultimately prove us wrong. A striking example is Prof. Dinesh Mohan's work. His relentless focus on road safety for the poor was met with fierce opposition. He rigorously accumulated evidence for compulsory helmets, advocated for reducing car speeds, and pushed for less expenditure on metro systems. Elite circles, be it his colleagues or civil society NGOs, accused him of stifling free will and undermining transport systems. But today, as public funds are being squandered on cruel subsidies for underused metro lines, his research stands vindicated. Prof. Mohan persisted, driven by both moral and technical will, to fundamentally upgrade road safety standards. In this process, he gifted the nation one of its finest interdisciplinary labs.
Maybe I'm subscribing to an overt bias for action, which also feels incorrect. Tech communities are obsessed with action, buzzing with movements like AI alignment and Effective Altruism. I haven't read much into AI Risk, though it feels like we are climbing the wrong hill. It seems like a moral justification to work on fashionable problems. A way to scale up ambitions under the guise of ethical concern. A moral buffer. Are technologists even equipped to foresee concrete policy decisions around AI risk and its philosophical aberrations? To be fair, I haven't engaged with the EA community enough to offer a critique, but I do find the moral calculus nauseating. I care about AI risks, but my deeper concern is for the immediate and local distress in the communities I live in. This might not be grand and all-encompassing, but I firmly believe that a better world is built from an amalgamation of several small, local, and sustained actions.
Like many others, I, too, went through a phase of questioning the value of my education. Social welfare and developmental politics in India have always intrigued me, and I wondered how my technological skills could contribute to "social good". Over the years, my answer to this question has evolved, and I will reserve those opinions for another post. A personal conviction operates here; an almost narcissistic sense of purpose drives us to discover directions that can be uniquely ours.
Along this journey, Prof. Milind Sohoni's talks and writings have had a major influence. I had the opportunity to speak with him once when he visited IITK. He spoke evocatively about the responsibilities of a student, professor, and university at large. He reiterated some of the key ideas from his talks – like running away from buzzwords, taking measurements seriously, and aiming to create more job descriptions. The last point stuck with me. Though I haven't worked towards it explicitly, it is something I've thought of and discussed with peers several times. Prof. Aaditeshwar Seth's book and work have also influenced my thinking.
One disconnection I have with ICTD literature is due to its heavy reliance on developmental economics. I simply don't have a taste for economics, game theory, or the assumption of rational human behaviour. It's not that I don't see the value. These frameworks are undeniably useful, and I respect them from a distance. But I just can't seem to grasp or enjoy them. A big chunk of welfare work revolves around subsidies, cash transfers, and economic reasoning. It feels like I'm missing an essential piece of the puzzle, yet I can't force myself to engage with it. The moment my friends start discussing economics, I mentally check out. Perhaps this is why I dislike GANs and their game-theoretic underpinnings.
Despite this disconnection, why am I still drawn to research in low-resource constraints and the Indian context? Part of the reason, of course, is that I'm from India, and I feel a deep affinity for the people and the land. But there's a technical fascination as well. I believe there's magic in designing with limited resources. I believe geographical constraints can spark creativity, enriching our modelling approaches.
Another question: why not work on Indian languages? I wouldn't mind, but there seems to be an overwhelming focus on Sanskrit. No one speaks Sanskrit in daily life. Sure, it's fascinating from a historical perspective, and there may be exciting connections to explore, but to me, it feels more like a cosmetic footnote. At worst, it becomes a forced political endeavour that detracts from research on the many other important, living languages spoken daily across India.
Mona Sloane, Emanuel Moss, Olaitan Awomolo, and Laura Forlano. 2022.
"Participation Is not a Design Fix for Machine Learning." (EAAMO
'22).
This paper introduced me to participatory action design and its
perils. It's easy for collaboration to devolve into coercion. What's
presented as a participatory process often turns out to be a hollow
exercise in theft and control. The paper continues to make me reconsider
my interactions with the communities I live in.
Harsh Nisar, Deepak Gupta, Pankaj Kumar, Srinivasa Rao Murapaka, A. V.
Rajesh, and Alka Upadhyaya. 2022. "Algorithmic Rural Road Planning in
India: Constrained Capacities and Choices in Public Sector." (EAAMO
'22)
A fabulous paper by
Harsh Nisar, someone I deeply
admire. It is not your typical post-hoc analysis piece with qualitative
interviews that pervades govtech research. It goes right into the middle
of implementation. The tech itself is simple: simulations on weighted
graphs. But the charm lies in the careful attention given to the lives of
data operators. I've recommended this paper to anyone wanting to get into
govtech.
Drèze, J. (2024). "The perils of embedded experiments." Review of
Development Economics, 28(4), 2059–2071.
https://doi.org/10.1111/rode.12999
Cautionary piece. It is common to see a technocratic blend of
economists, policymakers, and bureaucrats today in rural areas. Sure, they
can run experiments, publish papers, and win awards. But they risk
creating chaos for people on the ground.-
My fascination with sociology began during my undergraduate years when I took several courses in the field, taught by Prof. Jillet Sarah Sam. What I appreciate about the humanities, and sociology in particular, is that it offers an alternative way to understand the world and its people. It provides a distinct intellectual tradition to engage with meaningfully - a different aesthetic, a different prose, a different mode of criticism. Contrary to what many STEM advocates might assume, sociology is rigorously constrained by methodologies and logic. It is not merely an exercise in abstract thought or subjective interpretation.
It's crucial to grasp how disciplines outside of STEM function. ML (and CS) research thrives on collaboration, a point Terry Tao emphasized recently, as he dreams of seeing this ethos expand to mathematics. I appreciate the modularity of my field, but it also leaves me wondering if my personality can ever shine through in a collaborative landscape. Sociology, by contrast, often involves deeply personal, individual work, such as ethnographic projects that span over a year. My friends in sociology have this remarkable ability to infuse their writing with a voice that brims with intellectual character. I dream of matching their compelling prose someday.
Are there ways in which reading sociology could inform my primary interests in ML? Maybe, but the line of causality is unclear to me at the moment. Almost all our scientific ideas emerge from an internal thematic soup of political and moral wills. Our curiosity is shaped by the values we hold. Engaging with humanities offers a nice opportunity to sharpen my political self. Perhaps my understanding of public transport systems could someday influence how I model graph neural nets.
I, however, do not adhere to maxims like "studying the humanities makes you a better human!". That notion seems to suggest that studying science is somewhat destructive, and the humanities offer the only constructive path to examine the world. I strongly disagree. This mindset parallels arguments favouring fiction over non-fiction. Yet, one might wonder why Russia saw so many deaths during a time when humanist short fiction readership was at its height. I prefer to keep my expectations humble and try to honestly engage with research I love without unduly glorifying or rationalizing its benefits to the human race.
It will take me a long while to get fully accustomed to sociology's rigour. I hope to eventually contribute to the field someday, but not through the lens of computational social science. It feels limiting, as though it doesn't let sociology flourish on its own merits. I'm not against interdisciplinarity per se, and I'm open to computation playing a small role. But today's overwhelming focus (and capital) on computation seizes the narrative and dilutes the sociological imagination.
Guru, Gopal. (2002). How Egalitarian Are the Social Sciences in India?.
Economic and Political Weekly. 37. 5003-5009. 10.2307/4412959.
Do not accept epistemological charity from those above. While
fieldwork and real-world application are vital, we must strive to theorize
on our terms, allowing our perspectives to shine. Detach from the field
temporarily if need be.
Jaaware, Aniket. "The Silence of the Subaltern Student." Subject to
Change: Teaching Literature in the Nineties, edited by Susie Tharu,
Orient Longman, 1998, pp 107-124.
This is a rigorous and demanding text akin to the mathematical
rigour of ML papers. Yet, if engaged carefully, it can lead to profound
pedagogical insights. How do we improve curricula to serve the 90% of
students who remain silent, uninterested, or misunderstood? How do we
train them to think critically, not just about the subject but also its
values? Mere translations will not suffice.
Balagopal, K. (2000). A Tangled Web: Subdivision of SC Reservations in
AP. Economic and Political Weekly. 35. 1075-1081. 10.2307/4409078.
A masterclass in breaking down a complex question. Balagopal Sir's
prose is clear, structured, and filled with historical insights. EPW is an
outstanding journal.
Damodaran, Karthikeyan & Gorringe, Hugo. (2017). Madurai Formula
Films: Caste Pride and Politics in Tamil Cinema. South Asia
Multidisciplinary Academic Journal. 10.4000/samaj.4359.
This paper taught me to see films not as isolated entities but as
part of a larger aesthetic and political lineage. By extension, I also
enjoy literary analysis, as it seeks to articulate the inexpressible. It
is very challenging to describe art that is outside the realm of language.
Healy, K. (2017). Fuck Nuance. Sociological Theory, 35(2), 118-127.
https://doi.org/10.1177/0735275117709046
Although caste is a central concern in Indian sociology, it is
sometimes forced freely into theories under the guise of nuance. Healy's
provocative text critiques this perennial obsession with nuance in
sociology, questioning what makes a good theory and a good critic. Our
theorization should be ambitious, gutsy, intellectually interesting, and
gracefully allow space for criticism instead of hiding behind the
sophistry of nuance. Binaries can occasionally exist, leaving gradational
nuance for future work.
Phadke, Shilpa. (2013). Unfriendly bodies, hostile cities: Reflections
on loitering and gendered public space. Economic and Political Weekly.
48. 50-59.
Profoundly influential paper (and book) that anchors my
interactions with the city. While the gendered perspective is vital, at
its core, the book is about loving the city and how the city loves us
back. Loitering becomes the quiet meeting point of two unremarkable
entities: us and a not-so-smart city. I've revisited its chapters many
times, each reading feeling more personal. I'd love to have Shilpa Phadke
sign my copy. No other book has ever felt this close.
Graham, Stephen & Desai, Renu & Mcfarlane, Colin. (2013). Water
Wars in Mumbai. Public Culture. 25. 115-141.
10.1215/08992363-1890486.
Brutal divide between the rich and the poor with respect to civic
amenities. It is our moral responsibility to take small, thoughtful acts
to bridge these gaps.
Thatra, Geeta. (2016). Contentious (Socio-spatial) Relations: Tawaifs
and Congress House in Contemporary Bombay/Mumbai. Indian Journal of
Gender Studies. 23. 191-217. 10.1177/0971521516635307.
The power of documenting the voices of the few who have never
spoken before. We don't always need to generalize; sometimes, it's enough
to listen to those often left unheard. It also touches on some of my
favourite parts of Mumbai: Kennedy Bridge, Grant Road. Perhaps I'll write
more about this soon.
Goel, Rahul & Tiwari, Geetam. (2015). Access-egress and other
Travel Characteristics of Metro users in Delhi and its Satellite Cities.
IATSS Research. 10.1016/j.iatssr.2015.10.001.
Importance of cycles, feeder bus systems, public transport, and
urban histories/artifacts. A principled and empirically materializable
treatment.
Chaudhary, Latika. (2012). Caste, Colonialism and Schooling: Education
in British India. SSRN Electronic Journal. 10.2139/ssrn.2087140.
Reveals the surprising linkages of weak colonial policies with
India's broken public school system, particularly senior secondary
schools.
Kumar R. (2019). India's Green Revolution and beyond: Visioning
agrarian futures on selective readings of agrarian pasts. Economic and
Political Weekly, 54(34), 41–48.
The Green Revolution, an emblem of techno-solutionism, robbed
farmers of their agency, handing control to technocrats. Why do we blame
farmers for the scars left by colonial policies?
The article was prepared using the Distill Template
If you see mistakes or want to suggest changes, please contact me